История
- Первые компьютерные видеокарты имели лишь кадровый буфер: изображение
формировалось центральным процессором компьютера и программным
обеспечением, а карта отвечала за хранение кадров в буфере памяти и вывод их
на монитор
- повышение требований к качеству изображения привело к созданию
специализированного процессора, который занимается исключительно расчетом
и формированием изображения, освобождая от этих обязанностей центральный
процессор.
- Первые видеокарты, такие как IBM Monochrome Display Adapter (MDA) и Color Graphics Adapter (CGA) могли поддерживать только текстовый режим отображения или базовую цветную графику.
- Позже появились более совершенные графические карты, например, Video Graphics Array (VGA).
История
- Термин «GPU» впервые ввела компания Nvidia в 1999 году с выпуском GeForce 256.
- Это была первая видеокарта, которую продавали как GPU, поскольку она интегрировала механизмы трансформации, освещения, настройки/склейки треугольников и рендеринга на одном чипе.
- В 2006 году Nvidia представила GeForce 8800 GTX — первый GPU с унифицированной архитектурой.
- Вместо отдельных процессоров для вершинных и пиксельных шейдеров в нем находился пул процессоров общего назначения, которые могли выполнять обе задачи.
- Так GPU смог динамически распределять ресурсы в зависимости от рабочей нагрузки.
История
- Важным этапом развития GPU стало появление вычислений общего назначения на графических процессорах (GPGPU).
- Они расширили роль GPU за пределы рендеринга графики до общих вычислительных задач.
- Благодаря появлению таких языков программирования, как CUDA от Nvidia, а затем OpenCL, разработчики смогли использовать параллельную вычислительную мощность GPU для широкого спектра приложений — от научных симуляций до машинного обучения.
Первое поколение GPU
- GPU первого поколения являлись специализированными процессорами для
ускорения операций с трехмерной графикой и предназначались для построения
двумерных изображений трехмерных сцен в режиме реального времени
- Для увеличения скорости данных операций использовались аппаратная
реализация алгоритмов, в том числе отсечения невидимых поверхностей при
помощи буфера глубины, и аппаратное распараллеливание.
- GPU первого поколения принимали на вход описание трехмерной сцены в виде
массивов вершин и треугольников, а также параметры наблюдателя, и
формировали по ним на экране двумерное изображение сцены для этого
наблюдателя.
- Также они могли осуществлять текстурирование объектов, задание цвета
вершин, а также интерполяционную закраску. Все предшествующие этапы
выполнялись на CPU.
Первое поколение GPU
- История современных 3D-акселераторов, предназначенных для домашнего
использования, началась с компании 3Dfx.
- Видеокарты на основе процессора Voodoo Graphics, который впоследствии
стал называться Voodoo I, производства 3Dfx появились в 1996 году и надолго
сделали название производящей их компании синонимом слова 3Dакселератор.
- Типичное рабочее разрешение для
Voodoo I составляло 512 x 384
пикселей, максимальное – 640 x 480
при глубине цвета в 16 бит,
поддерживалось до 4 МБ
видеопамяти.
- Одним из факторов успеха молодой компании 3Dfx было использование
исключительно новой модели построения 3D-объектов, которая получила
название Glide.
- Glide основывался на библиотеке OpenGL.
- Сущность модели
заключалась в обмене информацией между чипом видеоплаты и видеопамятью,
при этом практически вся нагрузка ложилась на последнюю.
Первое поколение GPU
- Компании nVidia пришлось бросить все
силы на разработку 3D-ускорителей, дабы
обогнать 3Dfx в кратчайшие сроки.
- nVidia начала с процессоров Riva128 и Riva128ZX
- В 1998 году она выпустила новый чип –
Riva TNT. Riva TNT поддерживала 32-
битный цвет, которого не было в
акселераторах Voodoo (они работали
исключительно с 16-битными цветами),
интерфейс AGP 2x, и частоту работы чипа
90 МГц.
- Конкуренцию 3Dfx также составляла канадская компания ATI. В основе
первого поколения видеокарты Rage лежал чип Mach64. Для использования в
Rage он был доработан, обзавелся поддержкой 3D и функцией ускорения видео
формата MPEG-1.
- Rage II поддерживал библиотеки
Direct3D и OpenGL. Также была
добавлена поддержка формата
MPEG-2 и некоторых полезных
функций для рендеринга
Второе поколение GPU
- Отличается дополнительными возможностями программирования.
- Изначально
фиксированный алгоритм вычисления освещенности и преобразования
координат вершин был заменен на алгоритм, задаваемый пользователем.
- Затем появилась возможность писать программы для вычисления цвета пиксела
на экране.
- По этой причине программы для ГПУ стали называть шейдерами,
от английского shade - закрашивать.
- Первые шейдеры писались на ассемблере ГПУ, их длина не превосходила 20
команд, не было поддержки команд переходов, а вычисления производились в
формате с фиксированной точкой.
- По мере роста популярности использования шейдеров появлялись
высокоуровневые шейдерные языки, например, Cg от NVidia и HLSL от
Microsoft, увеличивалась максимальная длина шейдера
Второе поколение GPU
- Основоположником GPU принято считать главный чип
видеокарты nVidia GeForce 256, появившийся в августе 1999 года, и привнесший
в 3D-графику принципиально новые возможности.
- От предшествующих
графических чипов его отличала поддержка технологии Transform Lighting
(TL).
- Эта технология заключается в преобразовании
координат вершин в плоские координаты,
отображаемые на мониторе, и вычислении их
освещенности.
- Это весьма ресурсоемкие и
сложные вычисления, особенно при большом
количестве вершин.
- Ранее они выполнялись на
центральном процессоре, что отнимало
значительную часть процессорного времени,
либо на отдельных процессорах освещения и
трансформации.
Второе поколение GPU
- До 1999 года и первой модели под маркой
GeForce геометрическая информация сцены
обрабатывалась центральным процессором.
- Поэтому, благодаря появлению графических процессоров второго поколения, с
одной стороны, с CPU снималась часть нагрузки, что позволяло использовать
его для решения других, не менее важных задач.
- С другой стороны, появилась
возможность увеличения количества объектов и степени их прорисовки, что
позволило добиться нового уровня реалистичности в 3D-приложениях, а
особенно в компьютерных играх.
Второе поколение GPU
- В 2003 году на ГПУ впервые появилась поддержка вычислений с 32-разрядной
точностью.
- В качестве основного интерфейса программирования выделился Direct3D,
первым обеспечивший поддержку шейдеров.
- Появились первые приложения, использующие ГПУ для
высокопроизводительных вычислений, начало складываться направление
ОВГПУ.
- Для программирования ГПУ предложен подход потокового программирования.
Этот подход предполагает разбиение программы на относительно небольшие
этапы (ядра), которые обрабатывают элементы потоков данных
- Ядра отображаются на шейдеры, а потоки данных - на текстуры в ГПУ.
Третье поколение GPU
- GPU третьего поколения добавили возможности программирования к
графическим процессорам предыдущего поколения.
- Вершинные шейдеры позволяют определять параметры пикселя (освещенность,
прозрачность, отражающую способность, координаты, текстуру), исходя из
параметров вершин треугольника, содержащего его.
- Пиксельные шейдеры позволяют работать с каждым пикселем индивидуально, уже
после проведения геометрических преобразований.
- Обозначились основные производители дискретных графических процессоров:
компании nVidia и ATI.
- К представителям 3D-акселераторов третьего поколения можно отнести nVidia
GeForce 2 – 4, ATI Radeon 8500 – 9200.
- Изменения в GPU, произошедшие на
данном этапе, носили эволюционный
характер, значительных подвижек по
сравнению с предыдущим поколением не
наблюдалось.
Четвертое поколение GPU
- Представители следующего поколения GPU стали уже полностью
программируемыми.
- В качестве основного интерфейса программирования выделился Direct3D,
который первым обеспечил поддержку шейдеров (язык HLSL).
- OpenGL, начиная с версии 2.0, также добавляет поддержку высокоуровневого
языка программирования шейдеров GLSL.
- Появление операций ветвления и циклов позволило создавать более сложные
шейдеры.
- Появились приложения, использующие графические
процессоры для высокопроизводительных вычислений, таким образом, начало
складываться направление общих вычислений GPGPU (англ. General Purpose
GPU).
Четвертое поколение GPU
- Для программирования GPU был предложен SIMD-подход (англ. Single
Instruction Multiple Data).
- Этот подход предполагает, что группа параллельно работающих процессоров
осуществляют действия над разными данными, но при этом все они в
произвольный момент времени должны выполнять одинаковую команду.
- В качестве примеров GPU четвертого поколения можно назвать графические
процессоры моделей nVidia GeForce 5 – 7 и ATI Radeon 9500 – X800.
- На этом этапе наблюдается повсеместное вытеснение стандарта AGP более
быстрым PCI Express.
- В октябре 2006 года ATI официально стала графическим подразделением
AMD. ATI была куплена американской компанией за 5,4 миллиардов долларов США.
Пятое поколение GPU
- GPU пятого поколения характеризуются расширенными возможностями
программирования.
- На этом этапе GPU начинает поддерживать
геометрические шейдеры, которые, в отличие от вершинных, позволяют
обрабатывать не только одну вершину, но и целый примитив.
- Также появляется полная поддержка унифицированной шейдерной
архитектуры, за счет которой осуществляется более гибкое использование
ресурсов графического процессора.
- Кроме этого, GPU пятого поколения начинают поддерживать также операции с
двойной точностью.
Пятое поколение GPU
- Появляются специализированные средства, позволяющие взаимодействовать с
GPU напрямую, минуя уровень интерфейса программирования трехмерной
графики.
- Поддержка 32-битных вычислений с плавающей запятой становится
повсеместной, и это способствует активному росту направления GPGPU, для
которого создаются средства программирования.
- Появляются потоковые библиотеки программирования GPU (RapidMind,
Accelerator), а также первые коммерческие применения GPGPU (nVidia CUDA,
AMD FireStream).
- Более того, отпадает необходимость в использовании специализированного
физического ускорителя (англ. Physics Processing Unit, PPU) PhysX, поскольку
GPU получили возможность аппаратно ускорять физические расчеты и
освобождать, тем самым, CPU от излишних вычислений.
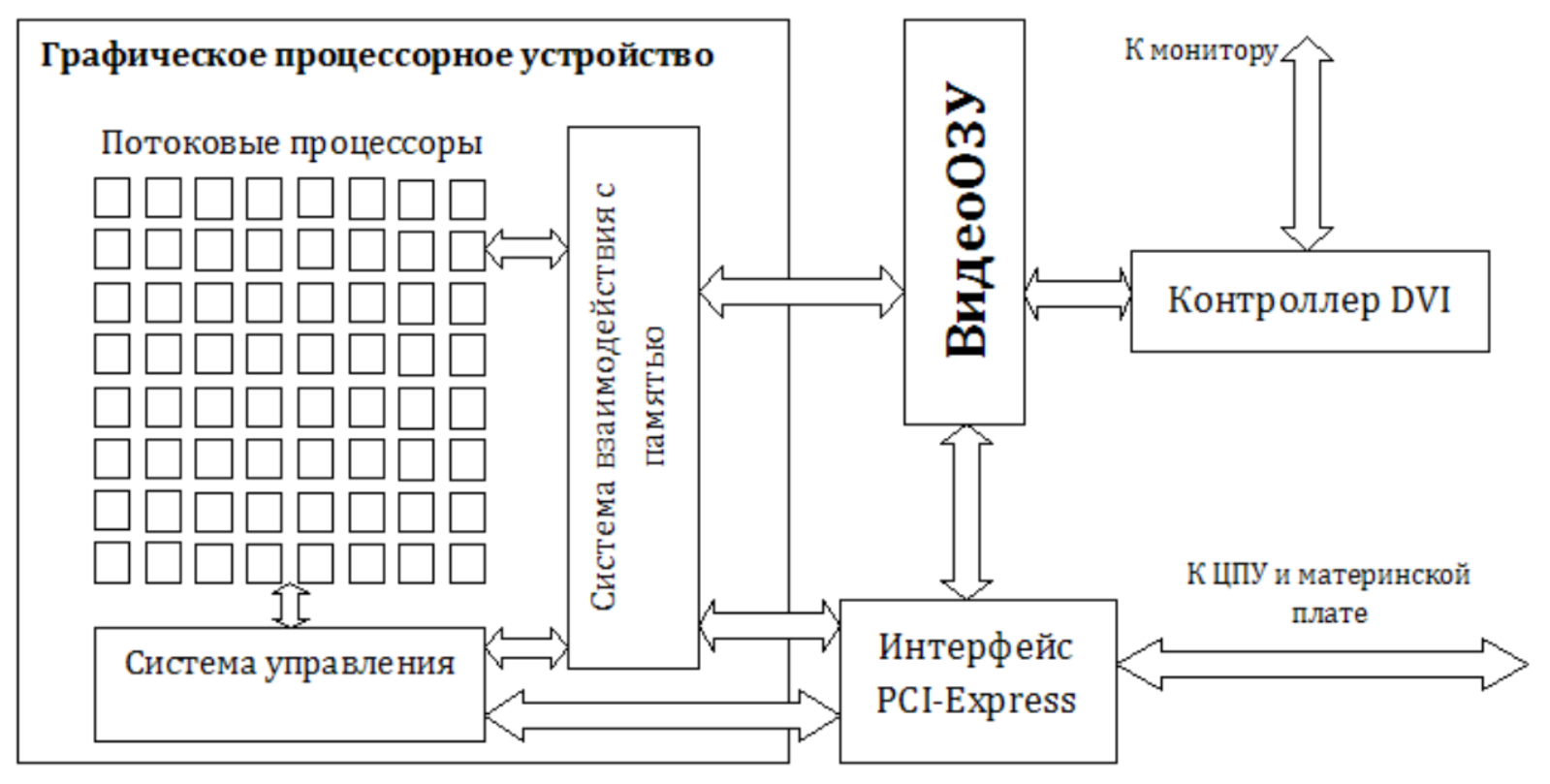
Архитектура
- Современные графические процессоры имеют довольно схожую архитектуру,
они содержат набор одинаковых вычислительных устройств - потоковых
процессоров, (ПП, Thread Processor), работающих с общей памятью
графического процессора (видеоОЗУ)
- Число потоковых процессоров, а также размер видеоОЗУ может быть
различным, в зависимости от модели GPU
- Все ПП синхронно исполняют одну и ту же команду, что позволяет отнести
GPU к классу SIMD (англ. single instruction, multiple data — одиночный поток
команд, множественный поток данных, ОКМД — принцип компьютерных
вычислений, позволяющий обеспечить параллелизм на уровне данных).
Архитектура
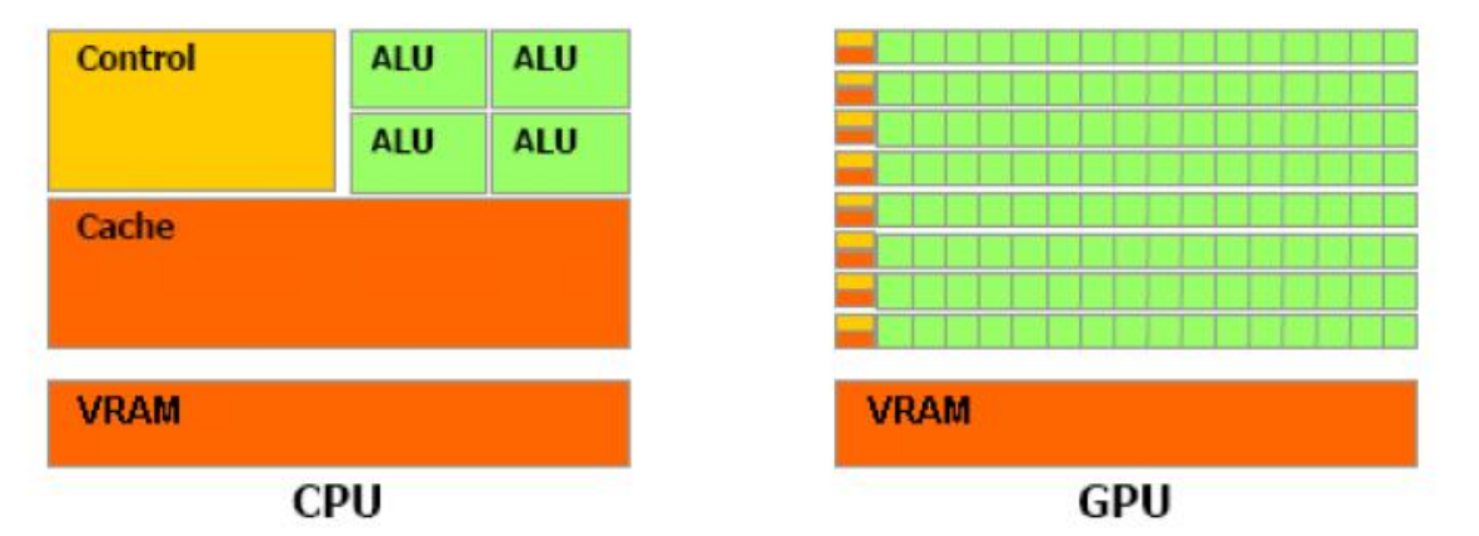
GPU vs CPU
- CPU: одно устройство контроля
исполнения, кэш и несколько арифметико-логических устройств
- GPU: состоит из набора мультипроцессоров, каждый из которых имеет
своё устройство контроля исполнения (Control), область разделяемой (Cache)
памяти, области регистров и значительно расширенный по сравнению с
обычным процессором набор арифметико-логических устройств (ALU).
G80

Семейство карт от NVIDIA
- GeForce — бренд семейства графических процессоров и чипсетов материнских
плат компании NVIDIA, ориентированного на потребительский рынок.
Графические процессоры GeForce используются преимущественно в
видеоадаптерах для персональных и переносных компьютеров.
- Quadro — серия видеокарт, разработанных фирмой NVIDIA для
пользователей профессиональных приложений
- Tesla — название семейства вычислительных систем NVIDIA на основе
графических процессоров с архитектурой CUDA, которые могут быть
использованы для научных и технических вычислений общего назначения.
Tesla строится на базе обычных графических процессоров, но, в отличие от
видеоускорителей, не имеет средств вывода изображения на дисплей.
- Tegra — семейство систем NVIDIA на кристалле (SoC — System-on-a-Chip),
как платформа для производства мобильных интернет-устройств, таких как
смартфоны, коммуникаторы, КПК и др. Кристалл Tegra объединяет в себе
ARM-процессор, графический процессор, медиа- и DSP- процессоры,
контроллеры памяти и периферийных устройств, имея при этом низкое
энергопотребление.
Архитектура G80
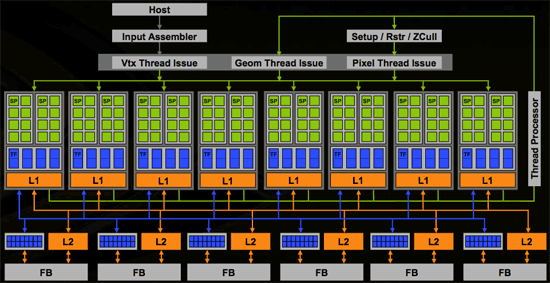
- SP – Streaming Processor
- TF – Texture Filtering
Unit
- L1/L2 – кэш
- ROP - Raster Operations
- FB – фрейм буфер
Архитектура G80
- В состав процессора G80 входят 128 вычислительных ядер (SP - зеленые) общей пиковой
производительностью 518 ГФлопс на тактовой частоте 1.35 ГГц.
- Нитевые ядра SP объединены в 8 блоков по 16 в каждом, управляемых менеджером
потоков и называемых потоковыми мультипроцессорами
- Каждая группа имеет кэш-память первого (L1) и второго уровней (L2) (причем кэш второго
уровня доступен для обращения всем остальным группам)
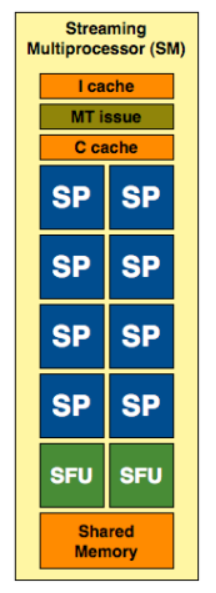
- Потоковый мультипроцессор содержит 8 ядер пиковой
производительностью 32 ГФлопс с поддержкой операций с числами в
формате с плавающей точкой стандарта IEEE 754, что делает ее
пригодной для серьезных, неигровых вычислений — например,
научных, статистических или экономических.
- два блока специальных функций — чтение/запись в память, обработка
текстур, выборки, переходы, вызовы процедур, операции
синхронизации;
- блок разделяемой памяти 16 Кбайт;
- блок множественных инструкций.
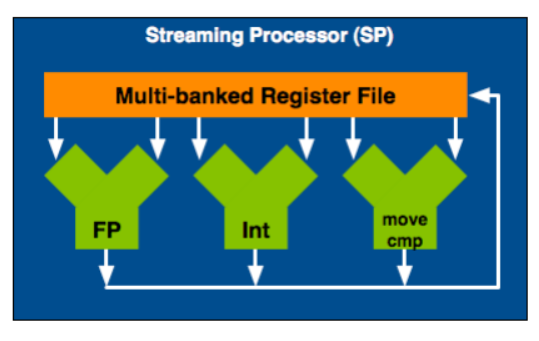
Потоковый процессор
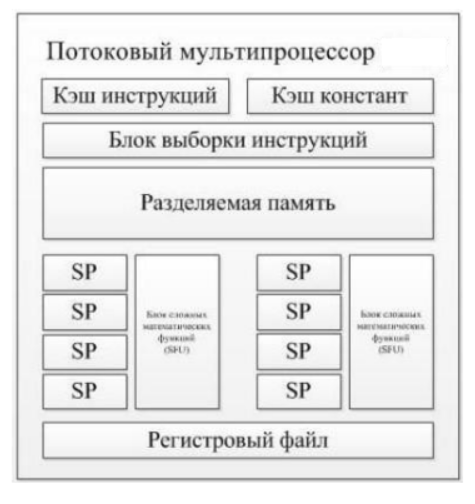
Потоковый процессор
- Любой из 128 потоковых процессоров
SP представляет собой обычное
вычислительное устройство, способное
работать с данными в формате с
плавающей запятой.
- Следовательно, он
не только способен обрабатывать
шейдеры любого типа – вершинные,
пиксельные или геометрические, но и
использоваться для просчета физической
модели или других расчетов, в рамках
концепции (CUDA), причем, независимо
от других процессоров.
- Регистровый файл – единый банк регистров, на каждом SP имеется 32Кб. Самый
быстрый тип памяти на графическом адаптере.
- Разделяемая память – специальный тип памяти, предназначенный для
совместного использования данных из одного блока. На каждом SM – 16Кб
разделяемой памяти.
Потоковый процессор
- Основные операции, поддерживаемые вычислительными ядрами, следующие:
- FADD, FMUL, FMAD, FMIN, FMAX, FSET, F2I, I2F — округление до
ближайшего четного, округление через 0, поддержка специальных чисел,
сброс денормализованных операндов и результатов до 0;
- целочисленные инструкции: IADD, IMUL24, IMAD24, IMIN, IMAX, ISET, I2I
SHR, SHL, AND, OR, XOR.
- Выполнение инструкций конвейеризировано.
- В состав ядер также входит блок специальных функций, который осуществляет
поддержку выполнения трансцендентных функций: RCP, RSQRT, EXP2, LOG2,
SIN, COS.
- Блок специальных функций позволяет выполнять аппроксимацию функций при
помощи квадратичной аппроксимации. Точность вычислений — порядка 22,5-
24,0 бит.
Потоковый процессор
- Результаты вычислений группы потоковых процессоров записываются в кэш второго
уровня и становятся доступны всем остальным группам.
- Таким образом, данные
циркулируют внутри процессора и покидают его, только когда все вычисления
завершены.
- Это устраняет задержки, возникающие при обращении к
видеопамяти.
Последовательность выполнений
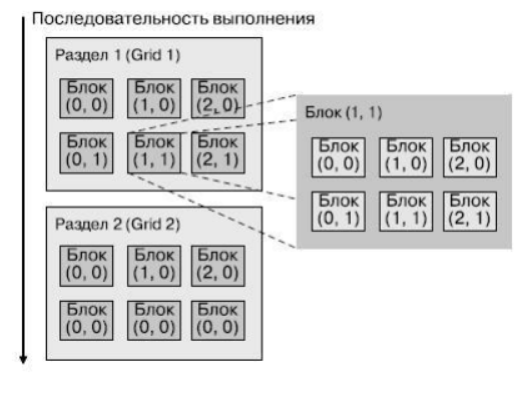
- При решении прикладных задач на
графическом процессоре разработчик
должен предварительно разбить задачу
на разделы (grids), причем один
раздел представляет собой один шаг из
последовательности шагов решения
задачи.
- В разделе задачи выделяются блоки,
результаты выполнения которых могут
быть получены параллельно — раздел
распараллеливается.
- В блоках выделяются элементы/нити, которые выполняются параллельно в
режиме взаимодействия, — эти элементы будут соответствовать нитям,
выполняющимся на отдельных ядрах
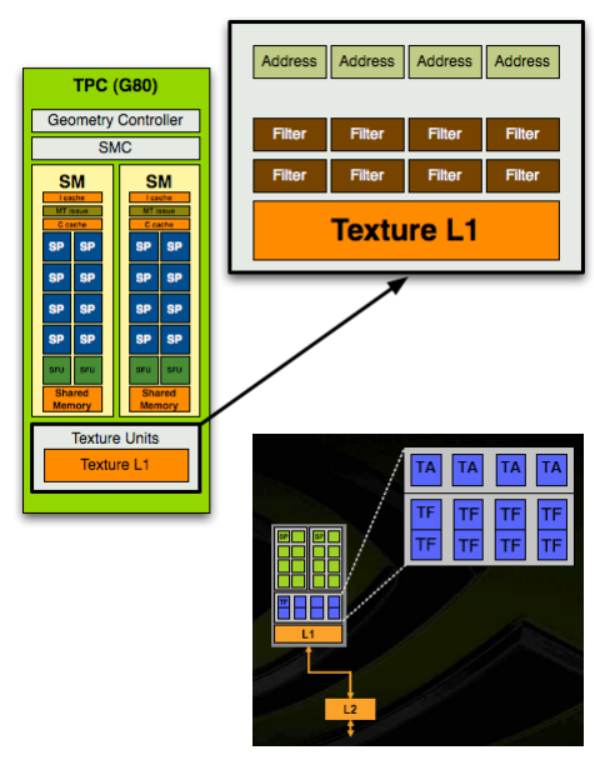
- На 8 блоков фильтрации
приходилось только 4 блока
адресации.
- Каждый из блоков имеет четыре
модуля адресации текстур
(определения по координатам
точного адреса для выборки - TA) и
ровно такое же количество модулей
билинейной фильтрации (TF).
GT200

Структура графического процессора GT200
- В основе чипа GT200 лежит базовая архитектура G80.
- Главное преимущество
нового GPU заключается в значительном увеличении количества
вычислительных блоков, что вылилось в почти двукратное увеличение числа
транзисторов – 1,4 млрд.
- Новый чип состоит уже из десяти
Texture Processing Clusters (TPC),
которых в прошлом поколении
графических процессоров было
всего восемь.
- Кроме того, количество потоковых
процессоров в TPC было
увеличено с 16 до 24.
- 8 блоков ROP
Структура графического процессора GT200
- общее количество потоковых процессоров равно 240 (24x10), текстурных
блоков – 80, блоков ROP – 32.
- Помимо увеличения количества вычислительных блоков и их организации они
были доработаны, а их производительность улучшена.
- Также было увеличено количество одновременно обрабатываемых потоков, а
изменения в регистровом файле повысили эффективность обработки сложных
шейдерных программ
- Точность вычислений с плавающей запятой теперь была
увеличена до 64 бит.
Структура графического процессора GT200
- Самый низкий уровень составляют
потоковые процессоры (SP –
Streaming Processor).
- Каждый SP
является самым настоящим
микропроцессором с очередным
типом исполнения команд,
обладающим полноценным
конвейером, парой ALU и FPU.
Структура графического процессора GT200
- Первым уровнем объединения является потоковый
мультипроцессор, или SM – Streaming Multiprocessor.
- Потоковый мультипроцессор представляет собой массив из
восьми SP, которые находятся в группе с двумя модулями
специальных функций SFU – Special Function Units.
- Каждый SFU содержит в своем составе четыре FPU, заточенные
для трансцендентных операций (sin, cos и т.д.) и интерполяции,
которые часто используются при расчетах, связанных, например,
с анизотропной фильтрацией.
- SFU является в отдельности таким
же полноценным микропроцессором, как и SP.
- В SM также входит диспетчер исполнения команд MT, который
занимается распределением нагрузки по SP и SFU внутри
группы.
- Вдобавок к SP, SFU и MT в мультипроцессоре содержится и небольшой объем
памяти (16 Кб - сделано это специально, так как каждый SP работает со своим
пикселем и общие объемы информации невелики), общий для всех процессоров.
Структура графического процессора GT200
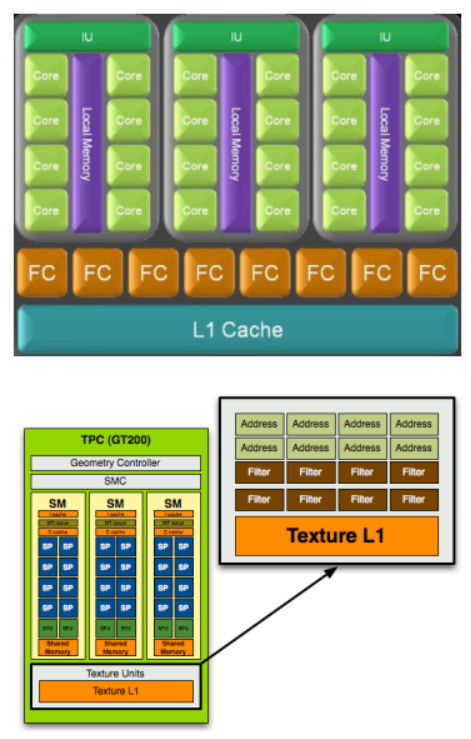
- Следующим уровнем объединения
является кластер SM, называемый
Texture/Processor Cluster (TPC).
- Внутри одного кластера шейдерные
процессоры объединены в три блокаюнита со своей выделенной областью
локальной памяти.
- Также на каждый кластер приходится по
8 текстурных блоков
Структура графического процессора GT200
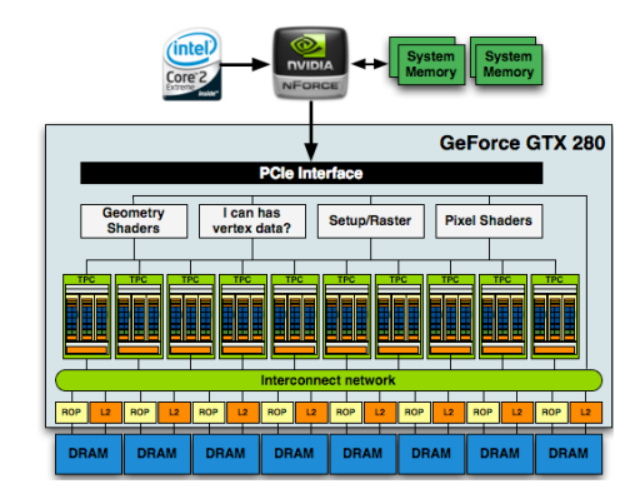 Уровнем выше располагается общая управляющая логика чипа,
распределяющая и планирующая нагрузки на различные кластеры, контроллер
PCI-Express 2.0 и шина Interconnect Network, соединяющая процессорную
мощь SPA с уровнем L2 кэша текстур и блоками обработки растровой графики
(Raster Operation Unit - ROP), которые в свою очередь уже имеют прямой
доступ к фрейм буферу.
Уровнем выше располагается общая управляющая логика чипа,
распределяющая и планирующая нагрузки на различные кластеры, контроллер
PCI-Express 2.0 и шина Interconnect Network, соединяющая процессорную
мощь SPA с уровнем L2 кэша текстур и блоками обработки растровой графики
(Raster Operation Unit - ROP), которые в свою очередь уже имеют прямой
доступ к фрейм буферу.
GF100

GF100
- 512 CUDA-процессоров
- 16 геометрических блоков
SM - мультипроцессор
- 4 блока растеризации
GPC-Graphics Processing Cluster
- 64 текстурных блока
- 48 модулей ROP
- 384-битный интерфейс памяти
GDDR5
- В GF100 внесено множество усовершенствований, направленных на обработку
сложной графической информации.
- Графический процессор GF100 построен на базе масштабируемой архитектуры,
в основе которой лежит применение объединенных в кластеры GPC (Graphic
Processing Cluster – кластеры обработки графики) потоковых мультипроцессоров
(SM, Streaming Multiprocessor).
GPC (Graphic Processing Cluster – кластеры обработки графики)
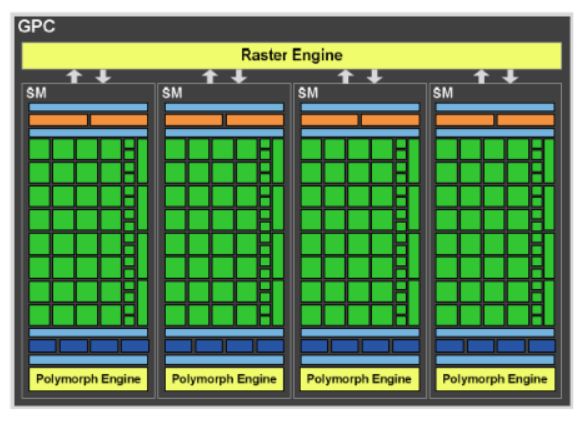
GPC (Graphic Processing Cluster – кластеры обработки графики)
- Каждый такой кластер содержит
четыре мультипроцессора (SM), а
также все необходимые блоки для
обработки геометрических данных и
текстурирования.
- Фактически, каждый GPC
представляет собой
самостоятельный графический
процессор, не имеющий лишь
собственной подсистемы памяти.
- GF100 состоит из четырех таких кластеров, совместно использующих шесть
контроллеров памяти, шесть модулей ROP (по 8 блоков ROP в каждом) и L2-кеш.
- В графическом процессоре GF100 реализованы средства
аппаратной поддержки теселляции, причем инженеры NVIDIA уделили этому
аспекту максимум внимания.
GF100
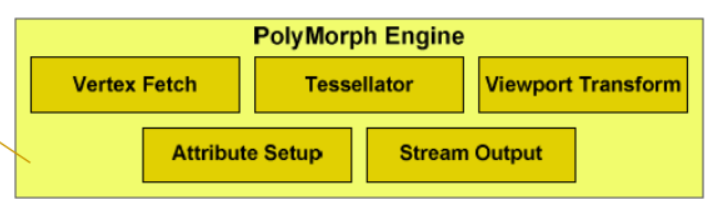
- Использование теселляции фундаментальным образом изменило распределение
нагрузки внутри графического процессора и вынудило инженеров NVIDIA
несколько изменить компоновку вычислительных блоков и ввести новый тип
блока – PolyMorph Engine.
- Каждый графический кластер (GPC) оснащен четырьмя такими блоками – по
одному на каждый мультипроцессор (SM).
- Каждый PolyMorph Engine выполняет пять стадий: выбор вершин, тесселяция,
преобразование координат, преобразование атрибутов, потоковый вывод.
PolyMorph Engine
- На первом этапе вершины выбираются из глобального буфера, после этого
вершина отправляется в мультипроцессор, где ее координаты преобразуются в
координаты сцены и определяется уровень тесселяции (аналог уровня детализации,
LOD).
- После этого вершина передается на второй этап – тесселяцию.
- На этом этапе
полигон разбивается на несколько новых, более мелких, по карте смещения
определяются их координаты.
- Полученные новые вершины вновь обрабатываются в мультипроцессоре и
передаются через потоковый вывод в память для дальнейшей обработки.
- После того, как геометрические данные обработаны в PolyMorph Engine они
передаются для растеризации в Raster Engine
- В этом блоке отфильтровываются невидимые примитивы (невидимые
поверхности), затем геометрические данные преобразуются в экранные точки,
которые в свою очередь сортируются и фильтруются по Z-координате.
- Каждый кластер (GPC) оснащен одним блоком растеризации, обрабатывающим до
8 точек за такт, то есть суммарная производительность GF100 составляет 32 точки
за такт – это в 8 раз больше, чем обеспечивал GT200.
GF100 SM
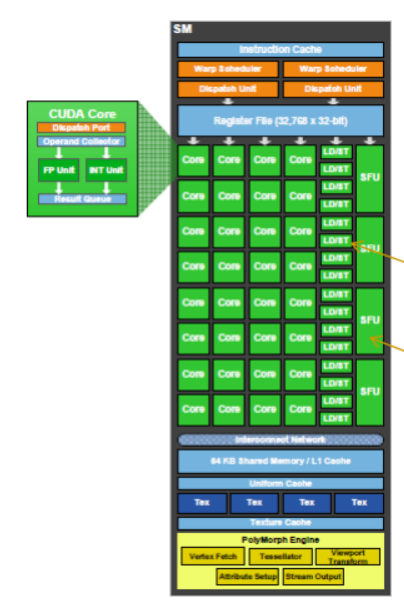
- Каждый мультипроцессор состоит из 32
вычислительных блоков CUDA. Каждый
процессор CUDA оснащен одним логическим
блоком ALU и одним FPU.
- Кроме того, каждый мультипроцессор оснащен 16
Load/Store-блоками, позволяющими определить
адреса данных в кеше или памяти для 16 потоков
за каждый такт
- Предусмотрены и четыре блока специальных
функций (SFU - Special Function Unit),
выполняющих такие операции как синус, косинус,
квадратный корень. Каждый SFU выполняет одну
операцию на поток за такт, так что ветвь (warp, 32
потока) выполняется за 8 тактов.
- Мультипроцессор организует потоки в ветви по 32 потока, для управления этими
ветвями используется два планировщика ветвей – две ветви могут выполняться на
одном мультипроцессоре одновременно.
- Планировщики GF100 передают по одной
инструкции от каждой ветви группе из 16 ядер
CUDA, 16 блоков LD/ST или четырех SFU.
- Кроме того, каждый SM оснащен четырьмя
текстурными блоками – каждый из них
отбирает до четырех текстурных семплов за
такт, результат может быть сразу же
отфильтрован – предусмотрена билинейная,
трилинейная и анизотропная фильтрация.
Общая память и кеш.
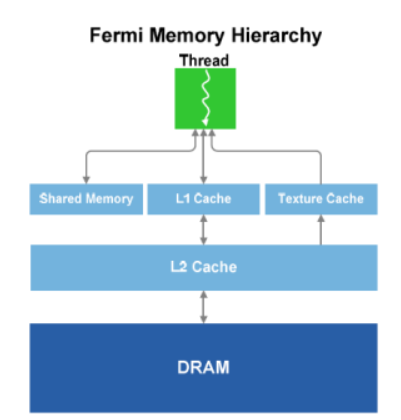
Общая память и кеш.
- Общая память – это быстрая, программируемая,
расположенная в микросхеме память, позволяющая максимально оптимизировать
обмен данными внутри потока.
- В GF100 помимо общей памяти используется
также L1-кеш, собственный внутри каждого
мультипроцессора (SM).
- L1-кеш работает в паре с общей памятью, в то
время как общая память предназначена для
алгоритмов с упорядоченным доступом к
памяти, L1-кеш ускоряет те алгоритмы, где
адреса данных не известны заранее.
- В GF100 каждый мультипроцессор оборудован 64 Кб памяти, которая может
быть поделена на 48 Кб общей памяти и 16 Кб L1-кеша или наоборот. Кроме
того, предусмотрен унифицированный L2-кеш объемом 768 Кб. Он
обеспечивает максимально быстрый обмен данными между различными
блоками