Архитектура RISC (на примере ARM)
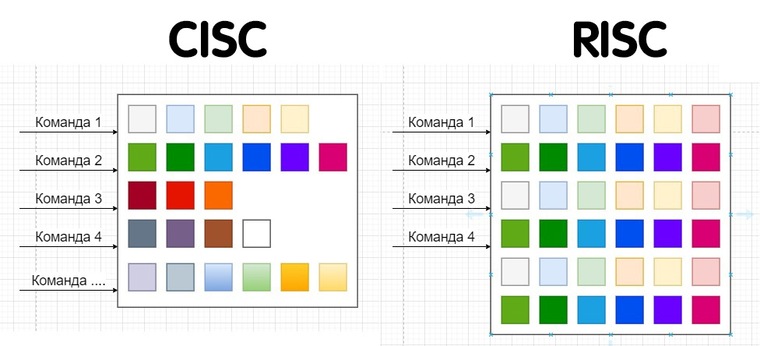
RISC vs CISC
- Reduced vs Complex Instruction Set Computer
- Простые операции
- Ограниченный набор простых команд (например, нет деления)
- Команда выполняется за один такт
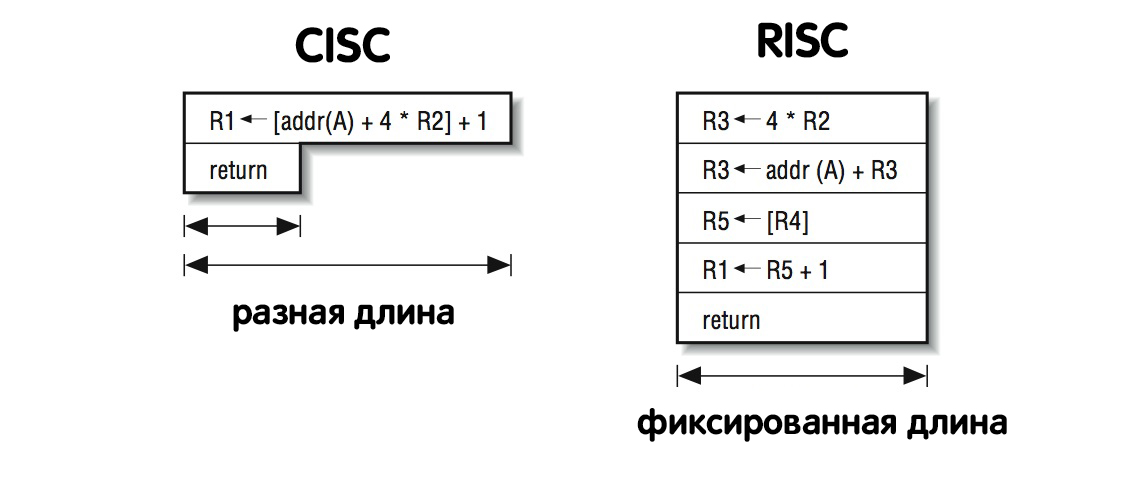
- Фиксированная длина команды (простота декодирования)
- Конвейер
- Каждая операция разбивается на однотипные простые этапы, которые выполняются параллельно
- Каждый этап занимает 1 такт, в т.ч. декодирование
- Регистры
- Много однотипных взаимозаменяемых регистров (могут использоваться и для данных, и для адресации)
RISC vs CISC
- Модель работы с памятью
- Отдельные команды для загрузки/сохранения в память
- Команды обработки данных работают только с регистрами
- Сложность оптимизаций перенесена из процессора в компилятор
- Производительность сильно зависит от компилятора
- Итого: более простое ядро, выше частота процессора
RISC vs CISC
- Команды сделали фиксированной длины
- увеличили число регистров, чтобы иметь большее пространство для работы с данными и реже обращаться к памяти.
RISC vs CISC
ARM
- ARM: Advanced RISC Machine
- Область применения: встраиваемые системы
- Разработчик: компания ARM Holdings, лицензирует дизайн процессора производителям оборудования
- Основные особенности:
- Энергоэффективность
- Низкая стоимость
- Относительно простое ядро
- Расширяемость
| Архитектура | Семейство процессоров | Год | Примеры устройств |
|---|---|---|---|
| ARMv1 | ARM1 | 1985 | |
| ARMv2 | ARM2, ARM3 | ||
| ARMv3 | ARM6, ARM7 | 1992 | |
| ARMv4 | StrongARM, ARM7TDMI, ARM9TDMI | 2003 | iPaq 4150 |
| ARMv5 | ARM7EJ, ARM9E, ARM10E, XScale | ||
| ARMv6 | ARM11 | 2007 | iPhone (orig, 3G) |
| ARMv7 | Cortex A8, Cortex A9 | 2008 | N900, iPhone (3GS, 4, 4S) |
| ARMv8 | Cortex-A53, Cortex-A57, Cortex-A72 | 2011 |
ARM v6
- Множественные Наборы Инструкций (Instruction Sets)
- ARM-режим (A32): 32-битные инструкции, полная производительность.
- Thumb-режим (T32): 16-битные инструкции для высокой плотности кода.
- Jazelle: Прямое выполнение Java-байткода (об этом ниже).
- Thumb-2: Это гибридный набор инструкций, который объединяет 16-битные и 32-битные инструкции в рамках одного режима выполнения.
ARM v6
- Улучшения Системной Архитектуры и Памяти
- Unaligned Data Support: ARMv6 впервые на аппаратном уровне поддерживала невыровненный доступ к данным (например, чтение 32-битного слова по адресу, не кратному 4).
- Раньше это приводило к исключениям, и ОС приходилось обрабатывать их программно, что было очень медленно.
- Это ускорило работу с памятью и упростило портирование кода с других архитектур (например, x86).
- Multiprocessing Extensions: В ARMv6 были заложены основы для многопроцессорных систем (SMP - Symmetric Multiprocessing)
- Были введены инструкции для эффективной реализации примитивов синхронизации, такие как LDREX и STREX (Load/Store Exclusive).
- Это основа для атомарных операций в современных многопоточных средах.
- Улучшения исключений (Exceptions) и прерываний (Interrupts): Была введена концепция "Base Restored Abort mode", которая ускоряла обработку ошибок доступа к памяти (aborts)
ARM v6
- SIMD-расширения
- В ARMv6 были представлены первые, довольно простые SIMD-инструкции (Single Instruction, Multiple Data).
- Они работали в основном с 8-битными и 16-битными данными, упакованными в стандартные 32-битные регистры.
- Инструкции SADD8, UADD16 и им подобные. Они позволяли, например, сложить 4 пары 8-битных чисел за одну операцию.
ARM-режим (A32)
- Это "родной" и самый мощный режим процессора.
- Длина инструкции: 32 бита.
- Состояние процессора: Определяется битом T в регистре CPSR. Для ARM-режима T=0.
- Полный доступ ко всем инструкциям: Доступны все команды процессора, включая работу с сопроцессорами, насыщающую арифметику и условное выполнение.
- Высокая производительность: Одна 32-битная инструкция может выполнить сложную операцию (например, сдвиг операнда в сочетании с арифметической операцией).
- Низкая плотность кода: 32 бита на инструкцию занимают много места в памяти. Для встраиваемых систем с ограниченной памятью это критично.
- Фиксированная длина: Упрощает декодирование и конвейеризацию.
; Условное сложение с сдвигом addgt r1, r1, r2, lsl #2 ; Если GT (Greater Than), то r1 = r1 + (r2 << 2) ; Загрузка 32-битной константы ldr r0, =0x12345678
Thumb-режим (T32)
- Создан для решения главной проблемы ARM-режима — большого размера кода.
- Длина инструкции: 16 бит (изначально).
- Состояние процессора: T=1 в CPSR.
- Высокая плотность кода: Размер кода сокращается примерно на 30-40% по сравнению с ARM-режимом. Это экономит дорогую память и улучшает использование кэша инструкций.
- Ограниченный набор команд: Многие сложные операции требуют нескольких инструкций. Например, нет условного выполнения (кроме ветвлений), ограниченный доступ к регистрам (только r0-r7), каждая инструкция следует своим правилам.
- Более низкая производительность: Часто требуется больше инструкций для выполнения той же задачи, что и в ARM-режиме.
- Идеален для 16-битной памяти: На 16-битной шине памяти одна 16-битная инструкция загружается за один такт, в то время как 32-битная инструкция ARM — за два.
Thumb-2
- Thumb-2 — это не отдельный режим, а расширение набора инструкций Thumb, представленное в ARMv6T2 и ставшее основным в ARMv7.
- Длина инструкции: Смешанная: 16-битные и 32-битные инструкции в рамках одного режима (T=1).
- Компилятор может свободно перемешивать компактные 16-битные инструкции для простых задач и мощные 32-битные инструкции (которые почти так же мощны, как и в ARM) для сложных операций.
- Плотность кода почти как у Thumb-1: В среднем на 25% меньше, чем у чистого ARM-кода.
- Производительность почти как у ARM: Благодаря 32-битным инструкциям производительность сравнима с ARM-режимом.
Jazelle — Специализированный режим
- Назначение: Прямое аппаратное выполнение байт-кода Java.
- Состояние процессора: Определяется битами J и T в CPSR. Для Jazelle J=1, T=0.
- Прямое выполнение: Когда процессор встречал специальную инструкцию BXJ (Branch and eXchange to Java), он переключался в Jazelle-режим и начинал интерпретировать поток данных (байт-код Java) как инструкции.
- Ускорение: Такой подход был в 5-10 раз быстрее чистого программного интерпретатора Java.
- Сложность: Аппаратная реализация была сложной и дорогой.
- Специализация: Был заточен только под Java ME.
- Появление Android: Android использовал свою виртуальную машину (Dalvik), которая работала с собственным байт-кодом (dex), а не с стандартным Java-байткодом.
- Рост производительности CPU: Производительность универсальных ядер ARM выросла настолько, что программные JIT-компиляторы (Just-In-Time) стали эффективнее аппаратной интерпретации.
ARM v7
- ARMv7 окончательно отказалась от устаревшей нумерации (ARM7, ARM9, ARM11)
- Cortex-A (Application): Для сложных ОС (Linux, Android, iOS). Имеют MMU (Memory Management Unit).
- Cortex-R (Real-Time): Для систем с жёсткими требованиями к времени отклика. Имеют MPU (Memory Protection Unit).
- Cortex-M (Microcontroller): Для встраиваемых систем и микроконтроллеров. Крайне низкое энергопотребление, нет MMU.
ARMv7-A (Application Profile)
- Для сложных вычислительных задач
- Максимальная производительность для выполнения сложных операционных систем и приложений.
- MMU (Memory Management Unit)
- Позволяет использовать виртуальную память.
- ОС может изолировать адресные пространства разных процессов друг от друга. Если одно приложение "упало", оно не затронет всю систему.
- Это обязательное требование для запуска Linux, Android, Windows и других ОС.
- Поддержка многопроцессорности (SMP - Symmetric Multiprocessing)
- Расширенные наборы инструкций
- Сложная система режимов и исключений
ARMv7-R (Real-Time Profile)
- Для детерминированных систем
- Предсказуемость и надежность.
- Гарантированное время отклика важнее абсолютной производительности.
- MPU (Memory Protection Unit):
- В отличие от MMU, не преобразует адреса (нет виртуальной памяти).
- Задача MPU — защищать регионы памяти (например, запрещать приложению писать в память ядра) и настраивать кэширование.
- Это быстрее и проще, чем MMU, что критично для детерминизма.
- Низкая латентность прерываний: Все механизмы оптимизированы для максимально быстрого реагирования на внешние события.
- Высокая надежность: Часто включают поддержку ECC (Error-Correcting Code) для кэша и памяти.
- Двойная система регистров (в некоторых ядрах): Например, в Cortex-R5/R7 есть две банкированных копии регистров (r0-r7). Это позволяет обработчику прерываний очень быстро переключиться на свой контекст, не тратя время на сохранение регистров в стек.
Банкирование регистров
- Банкирование регистров — это аппаратный механизм, при котором для разных режимов процессора предоставляются разные физические копии (банки) одних и тех же регистров.
- Минимизировать накладные расходы при входе в обработчик прерываний или исключений.
- При входе в обработчик прерывания процессор должен сохранить текущее состояние (значения регистров) в стек, чтобы потом восстановить его. Эта операция:
- Тратит время (такты процессора)
- Тратит энергию
- Увеличивает задержку (латентность) реакции на событие
- Решение с банкированием: Критически важные регистры имеют отдельные копии для каждого режима. При переключении режима процессор автоматически начинает использовать другую копию регистра, не разрушая предыдущую.
- Каждый привилегированный режим (FIQ, IRQ, SVC, ABT, UND) имеет собственный указатель стека (sp_
).
FIQ (Fast Interrupt Request) — Режим Быстрого Прерывания
- Обработка срочных, высокоприоритетных событий с минимально возможной задержкой.
- Когда активируется: При поступлении сигнала на вход FIQ процессора.
- Имеет собственные копии регистров R8_fiq - R12_fiq, R13_fiq (SP), R14_fiq (LR).
- Преимущество: Обработчик FIQ может начать работу немедленно, без сохранения контекста. Ему не нужно тратить время на PUSH R8-R12.
- FIQ — это один выделенный вход, в отличие от IRQ, который может быть от множества устройств.
- Типичное использование: Обработка событий, критичных ко времени:
- Обработка DMA (прямой доступ к памяти)
- Коммуникационные интерфейсы с жёсткими таймингами (например, последовательный порт)
- Обработка данных с АЦП (аналого-цифрового преобразователя)
IRQ (Interrupt Request) — Режим Обычного Прерывания
- Обработка стандартных прерываний от периферийных устройств.
- Когда активируется: При поступлении сигнала на вход IRQ процессора.
- Имеет собственные копии только R13_irq (SP) и R14_irq (LR).
- Обработчик должен сохранить в стек регистры R0-R12, которые он планирует использовать.
- Один вход IRQ может быть от многих устройств. Обработчик должен опросить Контроллер прерываний (PIC), чтобы определить источник.
- IRQ имеет более низкий приоритет, чем FIQ. IRQ может быть прерван FIQ.
- Типичное использование: Обработка прерываний от большинства периферийных устройств:
- Таймеры
- UART (последовательный порт)
- USB-контроллер
- Кнопки и т.д.
SVC (SuperVisor Call) — Режим Вызова Супервизора
- Реализация системных вызовов (syscalls). Это механизм, с помощью которого непривилегированный код (пользовательское приложение) может запросить услугу у ядра ОС.
- Когда активируется: При выполнении инструкции SVC (ранее называлась SWI).
- Это не прерывание от внешнего устройства, а сознательный вызов со стороны программы.
- Вызов SVC всегда переключает процессор из User-режима в SVC-режим (с привилегиями).
- Инструкция SVC имеет номер (например, SVC #0x10), который обработчик может прочитать, чтобы определить, какую услугу запрашивает программа.
- Типичное использование: Все системные вызовы ОС:
- Открытие/закрытие файлов (open, close)
- Выделение памяти (malloc, brk)
- Создание процессов (fork, exec)
- Ввод/вывод (read, write)
ABT (ABort) — Режим Прерывания по Ошибке Доступа к Памяти
- Обработка исключений, связанных с некорректным доступом к памяти.
- Prefetch Abort: Ошибка при попытке загрузки инструкции из памяти.
- Data Abort: Ошибка при попытке чтения или записи данных в память.
- Prefetch Abort и Data Abort используют один и тот же режим (ABT), но имеют разные вектора в таблице исключений.
- Специальные регистры (например, DFAR/IFAR — Fault Address Register и DFSR/IFSR — Fault Status Register) содержат детали ошибки (адрес, тип операции, причину).
- Причины возникновения:
- Обращение к невыровненному адресу (в архитектурах без поддержки)
- Попытка записи в ROM-память
- Обращение к несуществующей физической памяти
- Нарушение прав доступа MMU — самая частая причина в системах с виртуальной памятью.
UND (UNDefined) — Ремум Неопределенной Инструкции
- Обработка попытки выполнения неизвестной или не поддерживаемой инструкции.
- Когда процессор не может декодировать битовую последовательность в валидную инструкцию.
- Главное применение — эмуляция инструкций, которые не реализованы аппаратно.
- Отладка: Помогает выявлять ошибки выполнения (например, когда процессор начинает выполнять данные как код).
- Расширяемость: Позволяет добавлять "виртуальные" инструкции.
- Типичное использование:
- Эмуляция арифметики с плавающей точкой на процессорах без FPU
- Эмуляция новых инструкций на старом железе
- Реализация точек останова для отладчика
ARMv7-M (Microcontroller Profile)
- Для максимальной интеграции и эффективности
- Низкая стоимость, низкое энергопотребление и простота программирования
- Архитектура, ориентированная на прерывания: Обработка прерываний происходит аппаратно: процессор сам сохраняет контекст, загружает адрес обработчика из таблицы векторов и переходит к нему. Это невероятно быстро.
- Упрощенная модель программирования: Всего два режима: Thread (для прикладного кода) и Handler (для обработчиков прерываний).
- Нет банкированных регистров (кроме SP). Для сохранения контекста используется аппаратный механизм NVIC и "stacking".
- Высокая интеграция: Ядра Cortex-M предназначены для использования в микроконтроллерах (MCU), где память (Flash, SRAM) и вся периферия (UART, SPI, I2C, ADC, таймеры) находятся на одном кристалле с процессорным ядром.
- Управление энергопотреблением: Глубокие режимы сна (Sleep, Deep Sleep), позволяющие потреблять микро- и нановатты.
ARM v7
- Расширение Thumb-2 — Основная особенность
- В ARMv7 технология Thumb-2 стала основной и обязательной.
- Это гибридный набор инструкций, где 16-битные и 32-битные инструкции могут свободно смешиваться в рамках одного режима выполнения (Thumb).
- Размер кода остался почти таким же компактным, как у чистого Thumb-1, а производительность сравнялась с чистым ARM-кодом.
- Чистый ARM-режим (A32) практически перестал использоваться для прикладных программ. Thumb-2 стал стандартом де-факто.
ARM v7
- Advanced SIMD (NEON)
- NEON — это 128-битное SIMD-расширение (Single Instruction, Multiple Data), аналог SSE/AVX в x86.
- Значительное ускорение операций с мультимедиа (кодирование/декодирование видео и аудио), обработки сигналов, компьютерного зрения и т.д.
- Одна инструкция оперирует сразу несколькими данными. Например, одна инструкция может сложить 8 пар 16-битных чисел за такт.
- 16 128-битных регистров (также доступны как 32 64-битных регистра).
- Декодирование HD-видео, фильтры в камере, быстрые математические вычисления.
ARM v7
- VFP (Vector Floating Point) — Аппаратная поддержка чисел с плавающей точкой
- VFPv3/v4 — это сопроцессор для высокопроизводительных вычислений с плавающей точкой (float/double).
- Отличие от NEON: NEON предназначен для параллельной обработки целых чисел и fixed-point данных, а VFP — для точных операций с плавающей точкой, требующих соблюдения стандарта IEEE 754.
- Позволила эффективно выполнять 3D-графику, научные расчеты и сложные математические алгоритмы.
ARM v7
- Усовершенствования ядра и многопроцессорность
- Поддержка симметричной многопроцессорности (SMP). Появление первых 2-ядерных мобильных процессоров (напр., Cortex-A9).
- Усовершенствованный конвейер, позволяющий выполнять несколько инструкций за такт (суперскалярность).
- Cortex-A8 имел 13-стадийный конвейер и мог выпускать до 2 инструкций за такт. Cortex-A9 имел уже 8-стадийный конвейер с динамическим переупорядочением команд (out-of-order execution) и также 2 инструкции за такт.
ARM v8
- Две Основные Execution States (Состояния выполнения)
- Это фундаментальная концепция ARMv8.
- Процессор может работать в одном из двух состояний:
- AArch64
- 64-битный режим выполнения.
- Новый 64-битный набор инструкций A64.
- Использует 31 + 2 основных 64-битных регистра.
- Регистры теперь называются X0-X30, SP, PC.
- AArch32
- Обратная совместимость с ARMv7.
- Полная поддержка 32-битных приложений и ОС.
- Использует те же 32-битные наборы инструкций (A32, T32).
ARM v8
- Новая Модель Регистров в AArch64
- 31 Регистра общего назначения (X0-X30): 64-битные регистры. Могут использоваться как 32-битные (W0-W30).
- Стековый указатель (SP): Отдельный 64-битный регистр. Нет банкирования SP для разных режимов.
- Программный счетчик (PC): Отдельный 64-битный регистр. Недоступен для прямого обращения как обычный регистр (в отличие от ARMv7, где PC был R15).
- Регистр состояния (PSTATE): Заменил единый CPSR. Флаги и состояние системы теперь представлены отдельными полями.
- Больше регистров: 31 регистр общего назначения против 15 в ARMv7. Это уменьшает давление на стек и повышает производительность.
- Убрано банкирование регистров: В AArch64 нет отдельных регистров для FIQ, IRQ и других режимов (за исключением SP_ELx). Это упрощает архитектуру. Контекст теперь сохраняется в память программно.
ARM v8
- Упрощенная Модель Исключений и Уровни Привилегий (Exception Levels - ELx)
- ARMv8 заменила сложную систему режимов (User, IRQ, SVC и т.д.) на более чистую модель из 4-х уровней привилегий:
- EL0 (Exception Level 0): Пользовательский режим (User Mode). Здесь выполняются непривилегированные приложения.
- EL1 (Exception Level 1): Режим ОС / Ядра (Kernel Mode). Здесь выполняется код ядра операционной системы (Linux, Android, Windows).
- EL2 (Exception Level 2): Режим Гипервизора (Hypervisor Mode). Обеспечивает аппаратную виртуализацию. Позволяет запускать несколько ОС одновременно.
- EL3 (Exception Level 3): Режим Монитора Безопасности (Secure Monitor Mode). Самый привилегированный уровень. Управляет переключением между Secure World и Non-Secure World (TrustZone).
- Исключения (прерывания, системные вызовы) переводят процессор на более высокий уровень привилегий (например, из EL0 в EL1). Возврат из исключения — на более низкий.
ARM v8
- Усовершенствованный Набор Инструкций A64
- Набор A64 был очищен от устаревших и неудобных особенностей A32
- Убрано условное выполнение для большинства инструкций. Оставлено только для ветвлений (B.cond). Это было сделано для упрощения декодера и конвейера, что позволило повысить тактовую частоту.
- Фиксированная длина инструкций: Все инструкции A64 имеют длину 32 бита. Нет смешивания 16-битных и 32-битных инструкций, как в Thumb-2.
- Упрощенные непосредственные значения и сдвиги: Правила кодирования констант и сдвигов стали более логичными и предсказуемыми.
- Инструкции для манипуляции битами (например, BFM — Bitfield Move).
- Усовершенствованные инструкции загрузки/сохранения (например, LDP/STP — загрузка/сохранение пары регистров).
ARM v8
- Усовершенствования SIMD и Floating-Point
- В AArch64 NEON (Advanced SIMD) и FP (Floating-Point) стали обязательными и неотъемлемыми частями архитектуры.
- Регистры: 32 128-битных регистра V0-V31. Они используются как для целочисленных SIMD-операций (NEON), так и для операций с плавающей точкой (FP).
- Это означает, что любой процессор с AArch64 имеет аппаратную поддержку чисел с плавающей точкой и SIMD-ускорения "из коробки".
ARM v9
- самое новое семейство архитектуры
- добавлены такие возможности новые масштабируемые векторные SIMD (SVE2)
- матричные (SME/SME2) операции, а также функциональность трассировок.
- Armv9.4-A — это последний набор расширений Armv9.
ARM v9
- Arm Confidential Compute Architecture (CCA) — Фундамент Безопасности
- В традиционной модели доверяют всей операционной системе. Если злоумышленник получает контроль над ОС или гипервизором, он получает доступ ко всем данным и приложениям.
- Решение CCA: Введение концепции "Реальмов" (Realms).
- Это изолированное окружение выполнения для конфиденциальных данных и кода (например, биометрические данные, медицинские записи, проприетарные алгоритмы).
- Данные внутри Realms невидимы и недоступны даже для гипервизора или ОС, работающих в привилегированном режиме.
- Реализуется через новый механизм "Безопасной памяти", контролируемый аппаратно на уровне процессора. Гипервизор управляет ресурсами (память, процессорное время) для Realms, но не может читать или изменять их содержимое.
ARM v9
- Scalable Matrix Extension (SME / SME2)
- Если SVE/SVE2 — это "векторные" вычисления общего назначения, то SME — это специализация для матричных операций, лежащих в основе всех современных нейронных сетей.
- ИИ-нагрузки требуют огромного количества операций умножения-накопления над матрицами. Существующие SIMD-расширения не всегда эффективны для такого паттерна доступа к данным.
- Внеочередное выполнение операций: Позволяет процессору начать новую операцию с матрицей до завершения предыдущей, максимально используя вычислительные блоки.
- Тензорные буферы (Tile): Специальные аппаратные буферы для хранения фрагментов матриц (тайлов) прямо в процессоре, что минимизирует обращения к кэшу и памяти.
- Внешние произведения: Специализированные инструкции для эффективного перемножения матриц.
- Результат: До 5-кратного ускорения типичных рабочих нагрузок машинного обучения по сравнению с SVE2.
Пример процессорор ARM
Регистры
- 16 регистров общего назначения
- Размер: 32 бита, используются в целочисленных командах, полностью взаимозаменяемые
- Именование: r0 - r15
- Некоторые регистры имеют специальные имена и назначение:
- PC (r15) – Program Counter
- LR (r14) – Link Register
- SP (r13) – Stack Pointer
Регистры
- Регистры состояния
- CPSR (Current Program Status Register): флаги, обработка прерываний
- SPSR (Saved Program Status Register): хранит копию CPSR при обработке прерывания
- Доступ: команды MRS/MSR
- Контрольные регистры
- Изменения параметров кэширования, управления памятью, режимов процессора и т.п.
- Доступ: команды MRC/MCR
- Вещественные регистры (FPU и векторного сопроцессора)
Условные флаги

Флаги расположены в регистре CPSR (current program status register)

Установка флагов
- Если команда ALU имеет суффикс ’S’, то флаги будут установлены в соответствии с результатом команды.
subs r1, r2, #1 lsls r1, r2, #5 cmp r2, #1
Коды условий
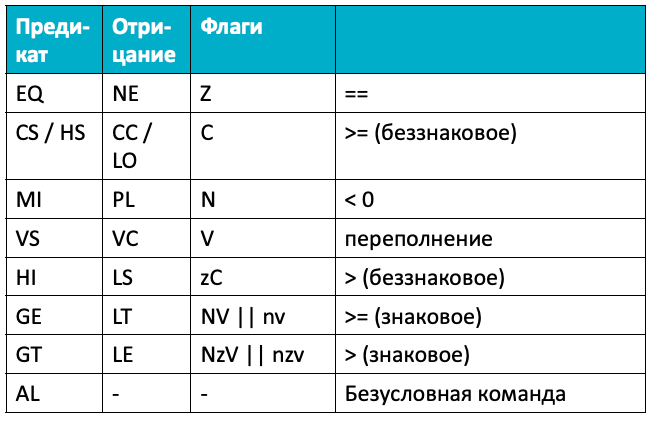
Условное выполнение
Почти все команды ARM могут быть записаны в условной форме. В этом случае условие приписывается после команды, и она будет выполнена, только если условие истинно.
addge r1, r1, r1 // вычисление модуля |r1 – r2|: subs r1, r1, r2 rsblt r1, r1, #0
Модуль сдвига
- Второй аргумент ALU-команд может быть представлен в виде
ARG2 = R shift_op B, где
- R – регистр
- B – величина сдвига (0-31)
- shift_op – один из LSL, ASL, RSL, ROR или RRX
add r1, r1, r1 lsl #2 // r1 = r1 + r1 *4 = r1 * 5
Представление констант
Второй аргумент ALU-команд может быть также константой, которая кодируется 12 битами (8 бит значение, 4 бита величина сдвига):
CONST_32 = CONST_8 << (2 * N), 0 <= N < 16
- and r1, r1, #255
- and r1, r1, #510 // 510 = 255 << 1 – нечетный сдвиг
- and r1, r1, #0xff00ff00 // значение «шире» 8 бит
- and r1, r1, #0xff000000
Режимы процессора ARM
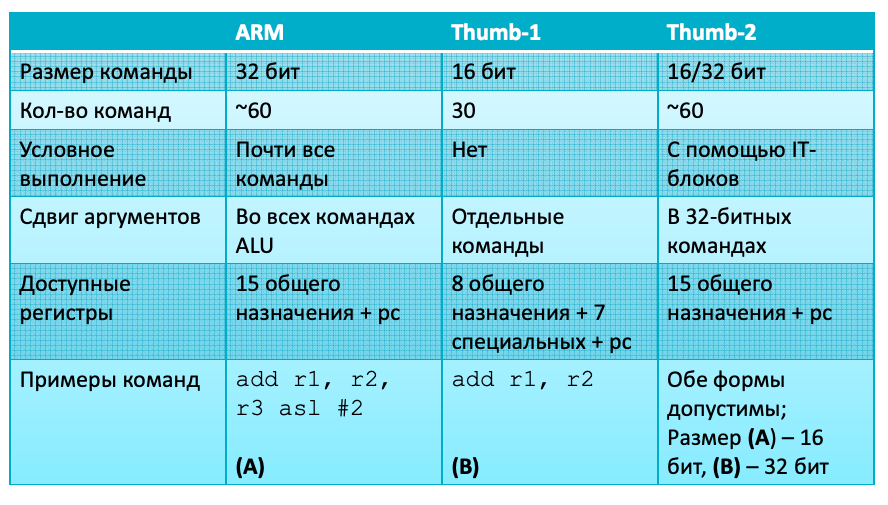
Команды работы с памятью
Команды загрузки/сохранения LDR / STR:
ldr r1, [r2, #+/-imm12] ldr r1, [r2, r1, [r2, +/-r3, shift imm5] // Примеры ldr r1, [pc, #256] ldr r1, [sp, r2, asl #2] L1: ldr r1, L1 + 248 ldr pc, [r1, r2, asl #2] // table-jump для switch
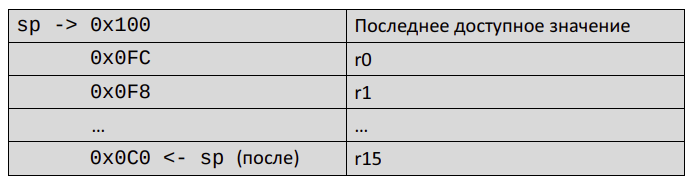
Команды работы со стеком
- Работа со стеком реализуется через команды stmdb/ldmia
push {r0 push {r0-r15} pop {r0 pop {r0-r15}
stmdb sp!, {r0, r15} ldmia sp!, {r0, r15}
Вызов функций
- Вызов функций выполняется при помощи команды bl – branch with link
- Текущее значение регистра pc сохраняется в регистре lr
- Возврат из функции выполняется с помощью команды bx lr
some_func:
push {lr}
…
pop {pc} bx lr
bl some_func
some_func:
bx lr
Конвейер современного ARM
- Cortex-A8
- Конвейер из 13 стадий
- 2 АЛУ устройства, 1 Load/Store, 1 Multiply
- Может выполнять до 2-х команд за такт
- Из них должно быть не более одной Load/Store и Multiply, причем умножение должно идти первым
- Cortex-A9: добавлено динамическое переупорядочение команд
Примеры описания времени выполнения команд на конвейере
- Этапы конвейера обознаются E1, E2, …, E5
- Перед началом каждого этапа команда может требовать готовности операндов в регистрах, а после – выдавать готовые операнды
- ADD r1, r2, r3
- r2, r3: требуются перед E2
- r1: после E2
Примеры описания времени выполнения команд на конвейере
- MOV r1, r2 asl #const
- r2: требуется перед E1
- r1: готов после E1
- Следствие 1: mov r2, r1; add r3, r2, r1 могут начать выполняться одновременно
- Следствие 2: add r1, r2, r3; mov r2, r1 (в обратном порядке) имеют задержку в 2 такта между командами
Селективный планировщик
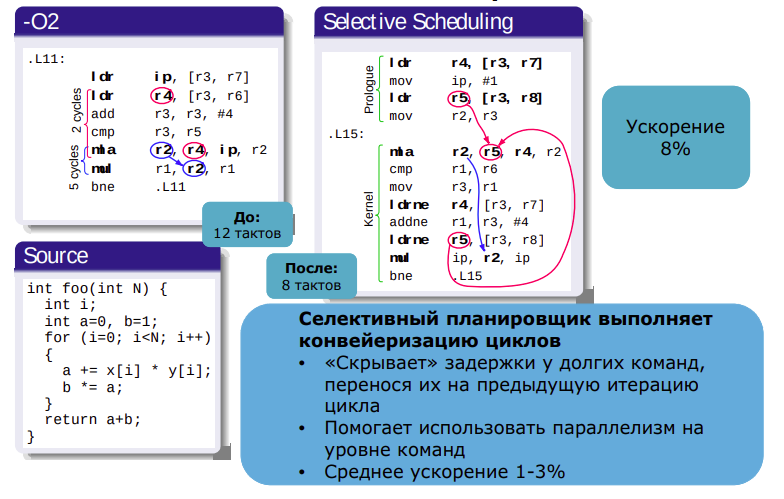
Улучшения кодогенерации для ARM Advanced SIMD (NEON)
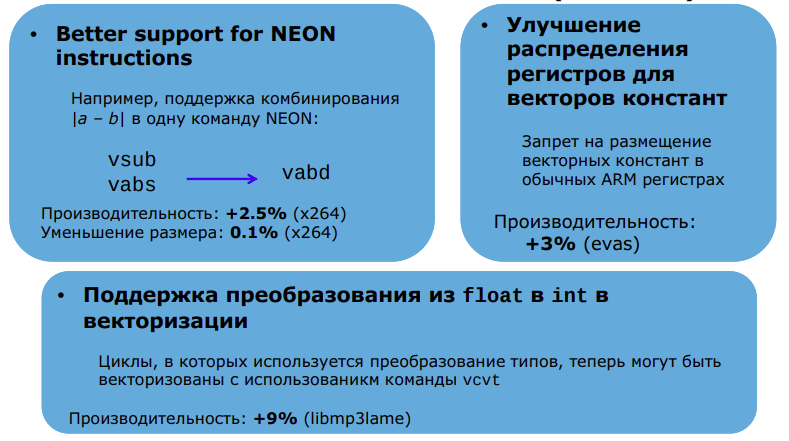
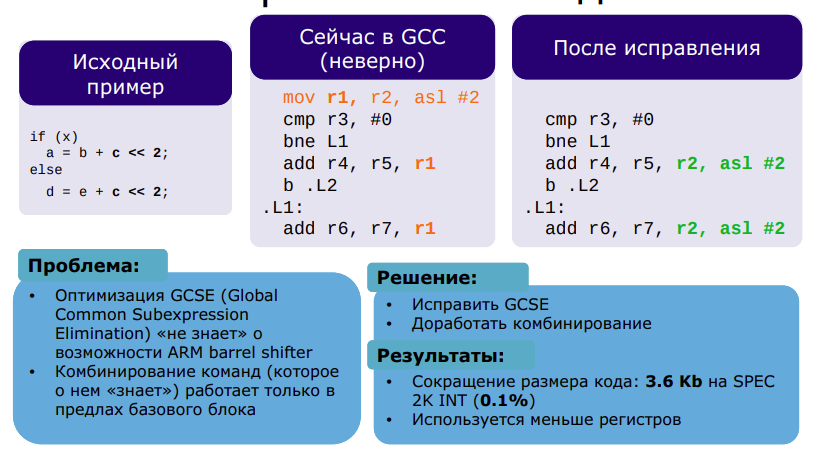
Улучшение оптимизации GCSE и комбинирования команд в GCC
RISC-V
- RISC-V - разработка Калифорнийского университета в Беркли.
- V - читается как "пять", пятая версия, получившая популярность.
- Идеи RISC, но открытая архитектура (x86 - только Intel, arm - нужно лицензирование).
- RISC-V International - фонд развития RISC-V.
- Февраль 2022 — Intel объявляет о том, что инвестирует 1 млрд $ в развитие RISC-V.
- Март 2022 — AMD размещает вакансии разработчиков RISC-V.
- По состоянию на 2022 год она насчитывает 2,400+ участников и ~300 компаний.
- Есть другие открытые архитектуры: Power, SPARC, openRISC.
Характеристики RISC-V
- RV32I означает архитектуру RISC-V, 32-разрядную
- I означает наличие целочисленной арифметики
- 47 базисных команд
- Эти команды фиксированной ширины по 32 бита.
- Это работа с памятью, арифметика, логика, работа с функциями.
- Архитектура поддерживает 32 32-битных регистра, архитектуру 64 бита (масштабирование очень важно), она будет называться RV64I.
Модульность RISC-V
- Базисная система команд может быть расширена. Возьмите только то, что вам нужно.
- M — целочисленное умножение и деление (RV32IM, то есть процессор, поддерживающий базисную RV32I и целочисленное умножение/деление);
- F, D — вычисления с плавающей точкой (F — float, D — double);
- A — атомарные операции с памятью (общая память);
- C — сжатые 16-битные инструкции (для устройств Интернета вещей (IoT));
- E — встраиваемые системы (например, только 16 регистров, это нужно для маломощных процессоров, в том числе для IoT (Internet of Things)).