Архитектура x86
Архитектура набора команд (ISA)
- Комбинация инструкций, которые понимает процессор, и регистров, которые ему доступны, называется архитектурой набора команды (Instruction Set Architecture, ISA).
- Количество инструкций, которые понимает процессор, ограничено.
- Невозможно определить собственную инструкцию.
- Существует фиксированное количество команд, которые понимает процессор.
- Одна архитектура микропроцессора трактует число 501012 как add r10, r12
- другая архитектура — как load r10, 12
Архитектура набора команд (ISA)
- Какие команды процессор может выполнять (например, сложение, чтение из памяти, переход).
- Как эти команды кодируются в бинарном виде (машинный код).
- Какие регистры (сверхбыстрая память внутри процессора) доступны.
- Как процессор работает с памятью.
- Обработку исключений и прерываний.
Примеры
- Intel и AMD, используют архитектуру набора команд x86.
- A12, A13, A14, M1 от Apple, понимают набор команд ARM.
- Программа компилируется под определенный набор команд.
Архитектура набора команд (ISA)
- Архитектура набора команд сильно влияет на архитектуру процессора.
- Использование определенной архитектуры набора команд может усложнить или упростить задачу по созданию высокопроизводительного или энергоэффективного процессора.
CISC, RISC
- x86 — это то, что называется архитектурой CISC (complex instruction set computing).
- ARM - архитектура RISC (reduced instruction set computer).
- Сейчас границы размыты, идеи заимствованы друг от друга.
CISC
- Раньше: память была очень дорогой. Компиляторы были плохие, а люди писали на ассемблере.
- Так как память была дорогой, люди искали способ минимизировать использование памяти.
- Одно из таких решений — использовать сложные инструкции процессора, которые делают много действий.
- Помогло программистам на ассемблере, так как они смогли писать более простые программы, ведь всегда найдется инструкция, которая выполняет то, что нужно.
CISC
Примеры сложных команд в x86:
- LOOP — уменьшает значение регистра CX на 1 и выполняет переход, если CX не равен нулю. Цикл в одной инструкции.
- REP MOVSB — команда для копирования блока памяти. Процессор сам увеличивает указатели, уменьшает счетчик и повторяет операцию, пока весь блок не будет скопирован.
- ENTER и LEAVE — сложные команды для создания и разрушения стекового фрейма процедуры.
- Команды для работы со строками, которые сами обрабатывают целые массивы.
CISC
Разнообразие способов адресации: CISC-процессоры предоставляют множество гибких способов вычисления адреса операнда в памяти. Это позволяет мощно обращаться к данным "на лету".
- Прямая адресация: MOV AX, [1000h] (загрузить в AX данные по адресу 1000h).
- Косвенная адресация: MOV AX, [BX] (загрузить в AX данные по адресу, хранящемуся в регистре BX).
- Базовая индексная со смещением: MOV AX, [BX + SI + 10h]. Это очень мощный режим, идеально подходящий для работы с массивами и структурами. Вычисление такого сложного адреса берет на себя процессор.
CISC
Команды, работающие непосредственно с памятью
- Один или оба операнда арифметической операции могут находиться прямо в памяти.
- ADD [BX], AX — прибавить значение регистра AX к данным в памяти по адресу в BX.
- В RISC для этого потребовалось бы три команды:
- LOAD R1, [BX] (загрузить данные из памяти в регистр R1)
- ADD R1, R1, AX (выполнить сложение в регистре)
- STORE [BX], R1 (записать результат обратно в память)
CISC
- Через некоторое время все стало сложным.
- Очень сложно создать процессор, который бы быстро выполнял эти запутанные команды с переменной длиной.
- Этап декодирования (преобразования команды в низкоуровневые сигналы для АЛУ) становится "бутылочным горлышком".
- Неравномерное время выполнения: Одни команды выполняются за 1 такт, другие — за десятки. Это крайне усложняет конвейеризацию (pipelining).
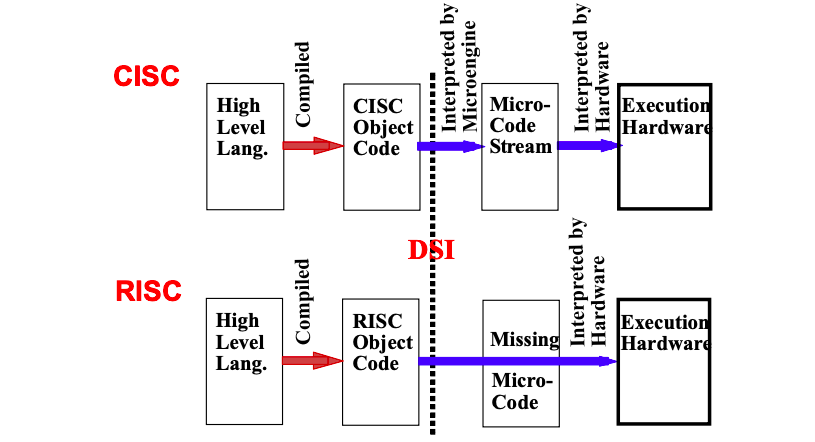
- Изначально ее решили с помощью микрокода.
Микрокод
- В программировании повторяющийся код выносится в отдельные подпрограммы (функции), которые можно вызывать множество раз.
- Идея микрокода очень близка к этому.
- Для каждой инструкции из набора создается подпрограмма, которая состоит из простых инструкций и хранится в специальной памяти внутри микропроцессора.
Микрокод
- Таким образом, процессор содержит небольшой набор простых инструкций. На их основе можно создать множество сложных инструкций из набора команд с помощью добавления подпрограмм в микрокод.
- Микрокод хранится в ROM-памяти (Read-Only Memory, только для чтения), которая значительно дешевле оперативной памяти.
Микрокод
- со временем начались проблемы, связанные с подпрограммами в микрокоде.
- В них появились ошибки.
- Исправление ошибки в микрокоде в разы сложнее, чем в обычной программе.
- Нельзя получить доступ к этому коду и протестировать его как обычную программу.
RISC
- Оперативная память стала дешеветь, компиляторы стали лучше, а большинство разработчиков перестало писать на ассемблере.
- большинство сложных инструкций CISC не используются большинством программистов.
- Разработчики компиляторов затруднялись в выборе правильной сложной инструкции.
- Вместо этого они предпочли использовать комбинацию нескольких простых инструкций для решения проблемы.
RISC
- Идея RISC заключается в замене сложных инструкций на комбинацию простых.
- Так не придется заниматься сложной отладкой микрокода.
- Вместо этого разработчики компилятора будут решать возникающие проблемы.
- RISC-код может быть непростым для человека.
- Архитектура RISC оптимизирована для компиляторов, но не для людей.
RISC
- Архитектура "Загрузка-Сохранение" (Load-Store Architecture)
- Арифметические и логические операции (ADD, SUB, AND, OR) могут выполняться только над данными, находящимися в регистрах.
- Память недоступна напрямую для вычислений.
- Для работы с данными в памяти существуют только две отдельные команды:
- LOAD — пересылает данные из памяти в регистр.
- STORE — пересылает данные из регистра в память.
- Это радикально упрощает устройство АЛУ (Арифметико-логического устройства) и систему управления процессора.
RISC, CISC
Архитектура x86
- x86 - это семейство архитектуры наборов команд, первоначально разработанные Intel на основе Intel 8086 микропроцессор и его вариант 8088.
- 8086 был представлен в 1978 году как полностью 16-битное расширение 8-битного 8080 микропроцессора Intel с сегментацией памяти в качестве решение для адресации большего объема памяти, чем может покрыть простой 16-битный адрес.
- Термин «x86» появился потому, что имена нескольких преемников процессора Intel 8086 заканчиваются на «86», включая 80186, 80286, 80386 и 80486 процессоров.
Общие сведения:
- Разработчик: Intel, AMD
- Биты: 16-бит, 32-бит и 64-бит
- Введены: 1978 (16-бит), 1985 (32-бит), 2003 (64-бит)
- Архитектура: CISC
- Тип архитектуры: регистр-память
Общие сведения:
- Переменная: от 1 до 15 байтов
- Ветвление: код условия (регистр состояния)
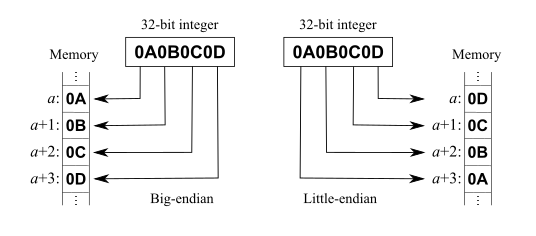
- Порядок байт: в основном little.
- Размер страницы: 8086 - i286 : нет. i386, i486 : страницы 4 КБ. P5 Pentium : добавлены страницы 4 МБ. (Legacy PAE : 4 КБ → 2 МБ). x86-64 : добавлены страницы 1 ГБ
Архитектура регистр-память
- Позволяет выполнять операции с памятью (или из нее), а также с регистрами
- Если архитектура позволяет всем операндам находиться в памяти, в регистрах или в комбинациях, это называется архитектурой «регистр плюс память».
- В подходе регистр – память один из операндов для операции ADD может быть в памяти, а другой - в регистре.
- Архитектура: загрузки/сохранения: оба операнда для операции ADD должны находиться в регистрах перед ADD.
- Примерами архитектуры регистровой памяти являются IBM System / 360, его преемники и Intel x86. Примеры архитектуры регистр плюс память: VAX
Реальный режим (Real Mode) — 16-бит
- Это режим, в котором работал исходный процессор 8086. Его модель памяти называется Сегментной моделью.
- Адресуемое пространство: 1 МБ (2^20 = 1,048,576 байт).
- Размер адреса: 20 бит. Но регистры были 16-битными! Возникла проблема: как с помощью 16-битного числа адресовать 1 МБ
- Физический адрес вычисляется по формуле: Физический адрес = (Сегментный адрес * 16) + Смещение
- Сегментный регистр (CS, DS, SS, ES): Содержит базовый адрес сегмента. Умножение на 16 (или сдвиг на 4 бита влево) означает, что сегменты выравнены по параграфам (границам 16 байт).
- Смещение (Offset): 16-битное значение, указывающее на конкретный байт внутри сегмента. Это значение находится в одном из универсальных регистров (например, IP, SI, DI, BX, SP, BP).
Реальный режим (Real Mode) — 16-бит
- CS = 0x1234, IP = 0x5678
- Физический адрес = (0x1234 * 16) + 0x5678 = 0x12340 + 0x5678 = 0x179B8
- Сегмент кода (Code Segment, CS): Указывается парой CS:IP. IP (Instruction Pointer) — указатель на следующую команду.
- Сегмент данных (Data Segment, DS): Используется по умолчанию для доступа к данным. Указывается парой DS:[SI/BX/...].
- Сегмент стека (Stack Segment, SS): Указывается парой SS:SP. SP (Stack Pointer) — вершина стека. BP (Base Pointer) используется для доступа к аргументам и переменным в стеке.
- Дополнительный сегмент (Extra Segment, ES): Часто используется для операций со строками, указывая на приемник (ES:DI).
- Проблема реального режима: Нет защиты памяти. Любая программа может получить доступ к любой области памяти, включая память ядра ОС, что приводит к нестабильности системы.
Защищенный режим (Protected Mode)
- Начиная с процессора 80286 (и полноценно с 386), появился защищенный режим. Его главные цели — защита памяти и поддержка виртуальной памяти.
- Виртуальное адресное пространство: До 4 ГБ для каждой программы (32-битная адресация). Каждой программе кажется, что она одна в системе и имеет в распоряжении всё адресное пространство.
- Изоляция: Программы не могут напрямую обращаться к памяти друг друга или к памяти ОС.
- Сегментация + Страничная организация: Сегментация используется для защиты, а страничная организация — для управления виртуальной памятью и подкачкой (swapping).
Защищенный режим (Protected Mode)
- Здесь сегменты — это не просто числа, умноженные на 16. Теперь это защищенные объекты.
- Дескрипторы: Каждый сегмент описывается структурой данных в памяти, называемой дескриптором. Дескриптор содержит:
- Базовый адрес (32 бита) — реальный начальный адрес сегмента в памяти.
- Лимит (предел) (20 бит) — размер сегмента.
- Атрибуты доступа: Уровень привилегий (0-3, где 0 — ядро ОС, 3 — приложение), тип сегмента (код/данные/системный), разрешение на чтение/запись/выполнение.
Защищенный режим (Protected Mode)
- Таблица дескрипторов: Все дескрипторы собраны в таблицы в памяти:
- GDT (Global Descriptor Table): Единственная таблица на всю систему. Содержит дескрипторы, общие для всех задач (например, сегменты кода и данных ОС).
- LDT (Local Descriptor Table): Может быть у каждой задачи (процесса) для описания её собственных сегментов.
- Селекторы: Сегментные регистры (CS, DS, etc.) в защищенном режиме содержат не базовый адрес, а селектор.
- Селектор — это индекс, указывающий на дескриптор в GDT или LDT.
- Также он содержит флаг, указывающий на GDT/LDT, и запрашиваемый уровень привилегий (RPL).
Защищенный режим (Protected Mode)
- Процесс преобразования (логический -> линейный адрес):
- Процессор берет селектор из сегментного регистра (например, CS).
- Находит соответствующий дескриптор в GDT/LDT.
- Проверяет права доступа (можно ли выполнять код из этого сегмента?).
- Берет базовый адрес из дескриптора.
- Прибавляет к нему смещение (из EIP или другого регистра).
- Получается линейный адрес (32 бита).
Защищенный режим (Protected Mode)
- Страничная организация (Paging) — виртуальная память
- Этот механизм преобразует линейный адрес (результат сегментации) в физический адрес. Именно он позволяет реализовать виртуальную память.
- Включение: Страничная организация включается отдельно установкой бита в управляющем регистре CR0.
- Страницы: Память делится на небольшие блоки фиксированного размера — страницы (обычно 4 КБ).
- Виртуальная память: Каждая программа работает со своим 4-ГБ линейным адресным пространством. ОС с помощью страничного механизма отображает виртуальные страницы программы на физические страницы в ОЗУ или на диске (в файле подкачки).
Защищенный режим (Protected Mode)
- Механизм преобразования (линейный -> физический адрес):
- Используется многоуровневая таблица страниц (чаще всего двухуровневая в 32-битном режиме):
- Линейный адрес делится на части:
- Директория (Page Directory): Старшие 10 бит — индекс в таблице каталогов страниц (PD).
- Таблица страниц (Page Table): Следующие 10 бит — индекс в таблице страниц (PT).
- Смещение (Offset): Младшие 12 бит — смещение внутри 4-КБ страницы.
- CR3 (управляющий регистр) содержит физический адрес каталога страниц (Page Directory) текущей задачи.
- Процессор: Использует старшие 10 бит линейного адреса как индекс в каталоге страниц, находит запись (PDE), которая указывает на нужную таблицу страниц
- Использует следующие 10 бит как индекс в таблице страниц, находит запись (PTE), которая содержит физический адрес начала страницы в памяти.
- Прибавляет к этому адресу 12-битное смещение, получая итоговый физический адрес.
Защищенный режим (Protected Mode)
Преимущества страничной организации:
- Swapping: Если страница не нужна, её можно выгрузить на диск, а в PTE отметить "страницы нет в памяти". При обращении к ней процессор сгенерирует исключение (#PF, Page Fault), и ОС загрузит страницу с диска обратно в ОЗУ.
- Разделяемая память: Одна физическая страница может быть отображена в адресные пространства нескольких процессов.
- Защита: Каждая страница имеет атрибуты (Read/Write/Execute).
64-битный режим (Long Mode)
В 64-битном режиме (x86-64) модель памяти была кардинально упрощена:
- Сегментация данных фактически отключена.
- Базовые адреса сегментов CS, DS, ES, SS принудительно устанавливаются в 0, а лимиты — в максимальное значение.
- Это создает плоское (flat) 64-битное адресное пространство. Логический адрес = линейный адрес.
- Сегментные регистры почти не используются, кроме особых случаев (например, FS и GS, которые ОС использует для указания на специальные структуры данных: в Windows GS указывает на структуру KPCR для ядра).
64-битный режим (Long Mode)
Расширение страничной организации
- Адресное пространство: 2^64 байт (теоретически), но обычно процессоры используют 48 или 57 бит для виртуальных адресов (256 ТБ или 128 ПБ).
- Усложнение таблиц страниц: Для адресации огромного пространства используются 4-уровневые (PAE paging) или даже 5-уровневые таблицы страниц.
- Размер страниц: Поддерживаются страницы разного размера (4 КБ, 2 МБ, 1 ГБ), что повышает производительность (меньше уровней таблиц для больших областей памяти).
Регистр состояния
- Регистр, содержащий флаги, дающие дополнительную информацию о результате в процессоре
- Примеры таких регистров включают регистр FLAGS в архитектуре x86
- Отдельные биты неявно или явно считываются и / или записываются инструкциями машинного кода, выполняемыми на процессоре.
- Регистр состояния позволяет инструкции выполнять действия в зависимости от результата предыдущей инструкции.
- Обычно флаги в регистре состояния изменяются в результате арифметических операций и операций манипулирования битами. Например, бит Z может быть установлен, если результат операции равен нулю, и очищен, если он не равен нулю.
Общие флаги
- Z, Нулевой флаг: Указывает, что результат арифметической или логической операции (или, иногда, загрузки) был нулевым.
- C, Флаг переноса: Позволяет добавлять / вычитать числа, превышающие одно слово, путем переноса двоичной цифры из менее значимого слова в наименее значимый бит более значимого слова по мере необходимости.
- S/ N, Знаковый флаг. Отрицательный флаг: Указывает, что результат математической операции отрицательный.
- V/ O/ W, Флаг переполнения: Указывает, что подписанный результат операции слишком велик, чтобы поместиться в ширину регистра с использованием представления с дополнением до двух.
Порядок байт
- Порядок байтов - это порядок или последовательность байтов в слове цифровых данных в памяти компьютера.
- Система с прямым порядком байтов хранит старший значащий байт слова по наименьшему адресу памяти и младший значащий байт по наибольшему.
- Система с прямым порядком байтов, напротив, хранит младший байт по наименьшему адресу.
регистры x86
- Исходные Intel 8086 и 8088 имеет четырнадцать 16- битных регистров.
- Четыре из них (AX, BX, CX, DX) являются регистрами общего назначения (GPR)
- К каждому из них можно обращаться как к каждому байтам (таким образом, как к старшему байту BX можно обращаться как к BH, а к младшему - к BL).
- SP (указатель стека) указывает на «верх» стека
- BP (базовый указатель) часто используется для указания на какое-то другое место в стеке, обычно выше локальные переменные
- Регистры SI, DI, BX и BP являются адресными регистрами
- Четыре сегментных регистратора (CS, DS, SS и ES) используются для формирования адреса памяти.
- указатель инструкции (IP) указывает на инструкцию, которая будет извлечена из памяти и затем выполнена; к этому регистру нельзя получить прямой доступ (чтение или запись) для программы.
Классификация
- 1 поколение — способность исполнять код i8086 (IA16).
- 1+ поколение — частичная паралеллизация исполнения команд, специализация ФУ.
- 2 поколение — поддержка виртуальной памяти, многозадачности и 32-битности (IA32).
- 2+ поколение — L1-кэш.
- 3 поколение — встроенный FPU, исполнительный конвейер (не обязательно для RISC-подобных микроопераций).
- 3+ поколение — умножитель частоты ядра.
Классификация
- 4 поколение — IPC>=2, специализация L1.
- 4+ поколение — SIMD: 4/2/1-байтовые целые (обозначено как 4i).
- 5 поколение — конвейеризованный FPU, OoO, L2-кэш.
- 5+ поколение — IPC>=3, SIMD: вещественные одинарной (SP) и двойной (DP) точности, 8/4/2/1-байтовые целые (SP+4i и DP+8i).
- 6 поколение — многоядерность, 64-битность (x86-64).
- 6+ поколение — встроенный контроллер памяти, L3-кэш.
Правила формирования поколений
- Процессор относится к определённому поколению в том случае, если у него присутствуют все признаки этого и всех предыдущих поколений.
- Правило образования исключений: процессор может быть продвинут вперёд на полпоколения, даже если у него отсутствует требуемая функциональность, но присутствует другая функциональность более позднего поколения.
Умножитель частоты
- ФАПЧ (PLL - Phase-Locked Loop) или "петля фазовой автоподстройки частоты".
- Множитель процессора (коэффициент умножения) — это число, на которое умножается частота шины.
- В результате получаем реальную (внутреннюю) частоту процессора.
- Например, частота шины (FSB) составляет 533 Mhz, коэффициент умножения — 4.5, получаем: 533 x 4.5 = 2398,5 Мгц.
- Почти у всех современных процессоров данный параметр является заблокированным на уровне ядра и не поддается изменению.
- Сложная система, которая синхронизирует фазы сигналов.
Умножитель частоты
- Тактовый генератор (Generator): Генерирует опорную частоту (это и есть базовая частота шины, например, 100 МГц).
- Делитель частоты (Divider): Делит высокочастотный сигнал, поступающий из процессора, на коэффициент умножения (N).
- Детектор фазы (Phase Detector): Сравнивает фазу опорного сигнала (100 МГц) и фазу сигнала, поделённого внутри процессора.
- Если фазы совпадают — система стабильна.
- Если есть расхождение — детектор выдаёт сигнал ошибки.
Умножитель частоты
- Фильтр (Loop Filter): "Сглаживает" сигнал ошибки, превращая его в постоянное напряжение.
- Управляемый генератор (VCO - Voltage-Controlled Oscillator). Он генерирует конечную, высокую частоту для ядра процессора. Частота VCO напрямую зависит от управляющего напряжения с фильтра.
- Если частота VCO слишком низкая — детектор фазы скорректирует напряжение, и VCO ускорится.
- Если частота VCO слишком высокая — напряжение скорректируется в другую сторону, и VCO замедлится.
- Система входит в равновесие, и VCO стабильно генерирует частоту, которая ровно в N раз превышает опорную.
Умножитель частоты
- Базовая частота (BCLK/FSB): Это "шаг" или "квант", от которого отталкивается вся система. В старых системах это была частота FSB. В современных — это Base Clock (BCLK), обычно равная 100 МГц. От неё зависят не только частота процессора, но и частоты памяти, шины PCIe и других компонентов (через свои множители).
- Коэффициент умножения (CPU Multiplier / Ratio): Целое число или дробное (например, x47), на которое умножается BCLK. Именно этот параметр в основном и определяет итоговую частоту процессора.
- Заблокированный множитель: У большинства процессоров множитель заблокирован сверху. Производитель устанавливает его на максимальном значении, и вы не можете его повысить для разгона.
- Разблокированный множитель: Процессоры серий Intel K/KF и AMD Black Edition/Ryzen (серия X и без индекса) имеют разблокированный множитель. Это позволяет легко увеличивать частоту процессора (разгонять его) простым изменением этого множителя в BIOS/UEFI, не затрагивая BCLK и не нарушая стабильность других компонентов.
Умножитель частоты
- Эпоха FSB (Front-Side Bus): В процессорах Pentium, Core 2 Duo использовалась шина FSB. Её частота (например, 266, 333, 400 МГц) умножалаcь на множитель, чтобы получить частоту ядра. Память тоже работала на частоте, зависящей от FSB.
- Современная архитектура (Intel и AMD): Концепция FSB устарела. Теперь используется Base Clock (BCLK ~100 МГц). Каждый компонент (ядро, кеш-память, оперативная память, шина PCIe) имеет свой независимый множитель по отношению к BCLK.
- Частота Ядра = BCLK * CPU Ratio
- Частота Памяти = BCLK * Memory Ratio
- Частота Шины PCIe = BCLK * PCIe Ratio (обычно фиксирован)
- Это сделало систему гибче и стабильнее. При разгоне можно менять только множитель CPU, не трогая BCLK, чтобы не "сломать" работу оперативной памяти и видеокарты.
Расширения: модуль с плавающей точкой (FPU)
- Часть процессора для выполнения широкого спектра математических операций над вещественными числами.
- x87 — это специальный набор инструкций для работы с математическими вычислениями, являющийся подмножеством архитектуры процессоров x86.
- инструкции не являются строго необходимыми для построения рабочей программы, но будучи аппаратно реализованными, общие математические задачи они позволяют выполнять гораздо быстрее.
- Например, в наборе инструкций x87 присутствуют команды для расчёта значений синуса или косинуса.
Расширения: модуль с плавающей точкой (FPU)
- Сопроцессор подключен к шинам центрального процессора, а также имеет несколько специальных сигналов для синхронизации процессоров между собой.
- Часть командных кодов центрального процессора зарезервирована для сопроцессора, он следит за потоком команд, игнорируя другие команды.
- Центральный процессор, наоборот, игнорирует команды сопроцессора, занимаясь только вычислением адреса в памяти, если команда предполагает к ней обращение.
- Центральный процессор делает цикл фиктивного считывания, позволяя сопроцессору считать адрес с адресной шины. Если сопроцессору необходимо дополнительное обращение к памяти (для чтения или записи результатов), он выполняет его через захват шины.
- После получения команды и необходимых данных сопроцессор начинает её выполнение.
Расширения: модуль с плавающей точкой (FPU)
- Регистры FPU организованы не в виде массива, а как регистровый стек.
- FPU представляет собой стековый калькулятор, работающий по принципу обратной польской записи
- Это означает, что команды всегда используют верхнее значение в стеке для проведения операций
- Доступ к другим хранящимся значениям обычно обеспечивается в результате манипуляций со стеком
Расширения: модуль с плавающей точкой (FPU)
- Внутри FPU числа хранятся в 80-битном формате с плавающей запятой (расширенная точность)
- Вещественные числа в трёх форматах: коротком (32 бита), длинном (64 бита) и расширенном (80 бит).
- Двоичные целые числа со знаком в трёх форматах: 16, 32 и 64 бита.
- Упакованные целые десятичные числа (BCD-числа) — длина максимального числа составляет 18 упакованных десятичных цифр (72 бита).
- не-число (англ. not-a-number (NaN)). Различают два вида не-чисел.
- SNaN (Signaling Not-a-Number) — сигнальные не-числа. Сопроцессор реагирует на появление этого числа в регистре стека возбуждением исключения недействительной операции.
- QNaN (Quiet Not-a-Number) — спокойные (тихие) не-числа. Сопроцессор может формировать спокойные не-числа в качестве реакции на определённые исключения, например, число вещественной неопределённости.
Расширения: модуль с плавающей точкой (FPU)
- В FPU можно выделить три группы регистров:
- Стек процессора: регистры R0..R7. Размерность каждого регистра: 80 бит.
- Регистр состояния процессора SWR (Status Word Register) — информация о текущем состоянии сопроцессора. Размерность: 16 бит.
- Управляющий регистр сопроцессора CWR (Control Word Register) — управление режимами работы сопроцессора. Размерность: 16 бит.
- Регистр слова тегов TWR (Tags Word Register) — контроль над регистрами R0..R7 (например, для определения возможности записи). Размерность: 16 бит.
- Указатель данных DPR (Data Point Register). Размерность: 48 бит.
- Указатель команд IPR (Instruction Point Register). Размерность: 48 бит.
Расширения: модуль с плавающей точкой (FPU)
- Команды передачи данных
- Команды сравнения данных
- Арифметические команды
- Трансцендентные команды
- Команды управления
Расширения: MMX
- MMX (сокр. от MultiMedia eXtensions - мультимедийные расширения)
- набор инструкций микропроцессора, предназначенных для ускорения обработки аудио- и видеоданных.
- Технология MMX разработана компанией Intel и впервые использована в 1997 году в процессорах Pentium MMX.
- Представляет собой 57 дополнительных команд и восемь 64-битных регистров
- Позволяет процессору за одну машинную операцию обрабатывать 64-битное бинарное слово которое может включать сразу несколько более мелких однотипных "частичек" - 8 байтов (1 байт = 8 битов), 4 слова (по 16 бит) или 2 двойных слова (по 32 бита).
- За счет этого в программах, разработанных с учетом поддержки MMX, процессору для обработки большого массива однотипных данных (которыми, по сути, и являются мультимедийные данные) требуется значительно меньше времени.
Расширения: MMX
- Например, при работе с цифровым изображением с глубиной цвета 16 бит процессор с MMX, в отличие от процессора без этого набора инструкций, может одновременно обрабатывать не один, а сразу 4 пиксела.
- По результатам синтетических тестов, MMX обеспечивает в среднем почти пятикратное увеличение производительности при работе с мультимедиа. На практике эти цифры несколько скромнее - около 1,5 - 1,7 раза (в оптимизированных приложениях).
- Недостатком MMX является то, что она может быть использована процессором только для обработки целых чисел.
- Кроме того, MMX имеет общие с сопроцессором регистры, так что одновременно задействовать инструкции MMX и инструкции сопроцессора процессор не может.
Расширения: 3DNow!
- 3DNow! — технология, разработанная компанией AMD. Впервые использована в 1998 году в процессоре AMD K6-2.
- 3DNow! является развитием технологии MMX.
- Она представляет собой 21 дополнительную инструкцию процессора, предоставляющую ему возможность оперировать 32-битными вещественными числами в регистрах MMX.
- Этим 3DNow! устранила один из главных недостатков MMX, которая ограничивалась ускорением только целочисленных операций одинарной точности. 3DNow! также существенно оптимизировала работу с кешем.
- По состоянию на 1998 г. 3DNow! позволила процессорам от AMD существенно опередить конкурентов от Intel в области обработки мультимедийных данных.
Расширения: SSE
- SSE (сокр. от Streaming SIMD Extensions) – технология, разработанная компанией Intel. SIMD расшифровывается как Single Instruction Multiple Data, что значит "одна инструкция - множество данных".
- Впервые SSE была использована в 1999 году в процессорах Pentium ІІІ с ядром Katmai. Изначально она называлась KNI (Katmai New Instructions).
- SSE стала своеобразным ответом Intel на разработанную годом ранее компанией AMD технологию 3DNow!.
- Так же, как и 3DNow!, SSE применяется процессором, когда нужно совершить одни и те же действия над разными данными и обеспечивает осуществление до 4 таких вычислений за 1 такт.
- Этим достигается существенный прирост быстродействия. При этом, данные могут быть как целочисленными, так и вещественными.
- Преимуществом SSE по сравнению с 3DNow! является использование собственных регистров, благодаря чему вместе с инструкциями SSE процессор может задействовать инструкции математического сопроцессора (регистры 3DNow! являются общими с сопроцессором и использовать их одновременно процессор не может).
Расширения: SSE
- 70 новых инструкций;
- 8 (в 64-битных процессорах - 16) 128-битных регистров, каждый из которых разделён на четыре 32-битных регистра с плавающей точкой;
- одного 32-битного (в 64-битных процессорах - одного 64-битного) регистра управления, необходимого также для проверки состояния SSE инструкций.
- Каждый 128-битный регистр SSE может одновременно хранить не только 4 32-битных числа. За один такт процесор может обрабатывать любые данные, помещающиеся в 128 бит (при условии использования оптимизированного программного обеспечения).
Расширения: SSE2
- SSE2 - набор инструкций, разработанный компанией Intel и впервые использованный ею в процессорах Pentium 4 (2000 - 2001 гг.).
- По сути SSE2 является дополнением к технологии SSE, разработанной Intel в 1999 году.
- Этот набор инструкций добавил к SSE 144 новые команды (в SSE их было только 70).
- дополнительные регистры не вводились.
- инструкции SSE2 используют все те же восемь 128-битных регистров SSE и позволяют процессору улучшить работу с ними.
- В частности, SSE2 дает возможность в регистрах SSE эффективно производить разнообразные операции со скалярными и упакованными типами данных, вещественными числами
- SSE2 включает в себя сложные дополнения к командам преобразования чисел, а также алгоритмы управления кэшем процессора, минимизирующие его загрязнения при обработке объёмных потоков данных.
Расширения: SSE3
- SSE3 является развитием технологий MMX, SSE, SSE2, представляет собой набор из 13 дополнительных команд, позволяющих процессору более эффективно использовать 128-битные регистры SSE.
- инструкцию по преобразованию чисел с плавающей точкой в целые числа;
- три инструкции дублирования данных;
- инструкцию загрузки невыровненных переменных;
- две инструкции одновременного сложения/вычитания;
- четыре инструкции горизонтального сложения/вычитания;
- две инструкции синхронизации потоков.
Расширения: AVX
- AVX (Advanced Vector Extensions) - расширение системы команд процессора, разработанное компанией Intel в 2008 году, которое, как и SSE, SSE2, SSE3, SSSE3, SSE4, стало дальнейшим развитием технологий SIMD (Single Instruction - Multiple Data, то есть "одна инструкция - множество данных").
- в 2 раза были увеличены регистры SIMD (со 128 до 256 бит)
- добавлен набор дополнительных 256-битных инструкций, выполняемых в этих регистрах
- При этом, сохранилась поддержка существующих 128-битных SSE-инструкций процессора, которые теперь использовали только первую половину новых 256-битных регистров.
- Благодаря расширению регистров, процессор с поддержкой AVX за каждый такт может обрабатывать до 2 раз больше информации в интенсивных вычислениях с плавающей точкой
Расширения: AVX
- Трёхоперандный синтаксис: Это фундаментальное улучшение с точки зрения программирования и эффективности.
- Старый синтаксис (SSE): DEST = DEST OP SRC
- Пример: ADDPS XMM0, XMM1 // XMM0 = XMM0 + XMM1
- Проблема: Исходный регистр-приёмник (XMM0) перезаписывается. Если его значение нужно было сохранить, приходилось делать лишнюю операцию копирования.
- Новый синтаксис (AVX): DEST = SRC1 OP SRC2
- Пример: VADDPS YMM0, YMM1, YMM2 // YMM0 = YMM1 + YMM2
- Преимущество: Исходные регистры (YMM1, YMM2) не разрушаются. Это позволяет создавать более эффективный код без лишних операций пересылки данных, что упрощает работу компиляторов.
- Инструкции AVX используют префикс V (например, VADDPS), чтобы отличаться от старых SSE-инструкций (ADDPS)
Расширения: AVX
- AVX Tax (Налог AVX): Когда процессор выполняет тяжёлые AVX-инструкции, он потребляет значительно больше энергии и, как следствие, сильнее нагревается.
- Автоматическое снижение частоты (AVX Offset): Чтобы оставаться в пределах теплового пакета (TDP), современные процессоры при длительной нагрузке AVX могут автоматически снижать свою тактовую частоту на несколько сотен мегагерц. Это необходимо для предотвращения перегрева.
- 256-битные исполнительные блоки внутри ядра процессора — это огромные, сложные и энергоёмкие схемы. Их активная работа требует большой мощности.
Расширения: AVX
- AVX2 (Haswell, 2013): Значительное развитие AVX.
- Добавила поддержку целочисленных операций на 256-битных регистрах (AVX1 работала только с float).
- Ввела мощные инструкции, такие как FMA (Fused Multiply-Add), которые выполняют операцию a = a + (b * c) за один такт, что критически важно для линейной алгебры.
- Расширила набор инструкций (сборки-разборки векторов, сдвиги).
- AVX-512 (Xeon, затем Core): Следующий шаг — удвоение до 512 бит.
- 512-битные регистры (ZMM): 16 чисел single-precision или 8 чисел double-precision за такт.
- Маскирование (opmask): Позволяет выполнять операции только над выбранными элементами вектора, исключая необходимость в условных переходах.
- Ещё больше новых инструкций для специализированных задач.
- Из-за очень высоких требований к энергии и площади кристалла поддержка AVX-512 в потребительских процессорах была неоднозначной, но остаётся ключевой для серверов и HPC.
Расширения: FMA
- FMA (Fused Multiply-Add) — это инструкция, которая выполняет операцию умножения с последующим сложением за одну операцию, без промежуточного округления.
- Базовая операция выглядит так: a = a + (b * c)
- Или в более общем виде: d = a + (b * c)
- Ключевое слово — "Fused" (Объединённое). Это означает, что операция выполняется как единое целое внутри процессора.
Расширения: FMA
- Без FMA (Раздельные операции)
- Умножение: temp = b * c
- Процессор выполняет умножение.
- Результат округляется до ближайшего представимого числа с плавающей запятой согласно стандарту IEEE 754.
- Промежуточный результат сохраняется в временную переменную temp.
- Сложение: a = a + temp
- Процессор выполняет сложение.
- Результат снова округляется.
- Две операции: Требуется два такта процессора (или два прохода через конвейер).
- Два округления: Каждое округление вносит небольшую ошибку (погрешность). Накопление таких ошибок может привести к значительной потере точности в длинных вычислениях.
Расширения: FMA
- С FMA (Объединённая операция)
- Объединённое умножение-сложение: a = FMA(b, c, a)
- Процессор выполняет всю операцию a + (b * c) за один такт.
- Округление происходит только один раз — в самом конце.
- Скорость: Одна операция вместо двух. Удвоение пропускной способности для цепочек умножений-сложений.
- Точность: Одно округление вместо двух. Это не просто "немного точнее", в некоторых случаях это кардинально меняет результат, делая его более корректным с математической точки зрения.
Расширения: AES-NI
- AES-NI — это набор инструкций для аппаратного ускорения алгоритма шифрования AES (Advanced Encryption Standard)
- специализированный "сопроцессор" внутри основного CPU, который заточен под выполнение операций, критически важных для шифрования и дешифрования по алгоритму AES.
- Вместо того чтобы выполнять сотни стандартных команд для каждого шага шифрования, процессор делает это одной специализированной инструкцией.
- Алгоритм AES состоит из множества раундов (10, 12 или 14 в зависимости от длины ключа), каждый из которых включает в себя
- SubBytes (замена байт по таблице)
- ShiftRows (перестановка строк)
- MixColumns (сложение и умножение в поле Галуа)
- AddRoundKey (сложение с ключом)
Расширения: AES-NI
- AES-NI — это набор инструкций для аппаратного ускорения алгоритма шифрования AES (Advanced Encryption Standard)
- специализированный "сопроцессор" внутри основного CPU, который заточен под выполнение операций, критически важных для шифрования и дешифрования по алгоритму AES.
- Вместо того чтобы выполнять сотни стандартных команд для каждого шага шифрования, процессор делает это одной специализированной инструкцией.
- Алгоритм AES состоит из множества раундов (10, 12 или 14 в зависимости от длины ключа), каждый из которых включает в себя
- SubBytes (замена байт по таблице)
- ShiftRows (перестановка строк)
- MixColumns (сложение и умножение в поле Галуа)
- AddRoundKey (сложение с ключом)
Расширения: AES-NI
- Эти операции, особенно в поле Галуа (GF(2⁸)), не очень эффективны для общего процессора.
- В результате шифрование/дешифрование становится "узким местом", потребляя значительные ресурсы CPU и ограничивая скорость работы приложений, использующих шифрование.
- AES-NI решает эту проблему, предоставляя специальные инструкции, которые выполняют целые раунды AES или их ключевые части за один такт процессора.
Расширения: AES-NI
- Набор состоит из шести инструкций, которые работают с регистрами SSE (XMM):
- AESENC (AES Encrypt) — Выполняет один раунд шифрования.
- AESENCLAST (AES Encrypt Last) — Выполняет финальный раунд шифрования.
- AESDEC (AES Decrypt) — Выполняет один раунд дешифрования.
- AESDECLAST (AES Decrypt Last) — Выполняет финальный раунд дешифрования.
- AESKEYGENASSIST (AES Key Generation Assist) — Помощь в генерации раундовых ключей из основного ключа.
- AESIMC (AES Inverse Mix Columns) — Выполняет операцию Inverse Mix Columns для подготовки ключей к дешифрованию.
Расширения: AES-NI
- Скорость: Обработка данных ускоряется в 3–10 раз по сравнению с чисто программной реализацией.
- Загрузка CPU: Нагрузка на процессор при шифровании одного и того же потока данных снижается в 5–10 раз. Это критически важно для серверов, которые одновременно обслуживают сотни или тысячи зашифрованных соединений.
- Энергоэффективность: Поскольку задача выполняется быстрее и меньшим количеством инструкций, процессор тратит меньше энергии на шифрование, что увеличивает время автономной работы мобильных устройств.
Расширения: AES-NI
- Полнодисковое шифрование (FDE): BitLocker (Windows), FileVault (macOS), dm-crypt/LUKS (Linux).
- Без AES-NI работа с зашифрованным диском могла бы приводить к заметным "подтормаживаниям" системы. С AES-NI разница в производительности между зашифрованным и незашифрованным диском практически незаметна для пользователя.
- Протоколы HTTPS (TLS/SSL), VPN (OpenVPN, IPsec, WireGuard), SSH.
- Любой веб-сервер (например, Google, Cloudflare), обрабатывающий миллионы HTTPS-запросов в секунду, был бы неспособен это делать без AES-NI.
- Шифрование данных "на лету" (transparent data encryption) в СУБД, таких как Microsoft SQL Server, Oracle.
- Зашифрованные виртуальные диски и контейнеры (VeraCrypt).
Расширения: AES-NI
- Intel: Впервые появилось в процессорах на микроархитектуре Westmere (2010 год). Сегодня поддерживается практически во всех процессорах для клиентов и серверов, начиная с Intel Core i5/i7 и Xeon.
- AMD: Добавили поддержку, начиная с микроархитектуры Bulldozer (2011 год). Поддерживается всеми современными процессорами Ryzen и EPYC.
- Проверка поддержки: В ОС Windows можно проверить наличие AES-NI с помощью утилиты CPU-Z (вкладка "Instructions"), в Linux — командой grep aes /proc/cpuinfo.
Расширения: Intel SGX
- Intel SGX (Software Guard Extensions) — это набор инструкций, который позволяет создавать защищённые области памяти, называемые энклавами (enclaves).
- Код и данные внутри энклава изолируются и шифруются аппаратно, так, что они становятся недоступными для любого другого программного обеспечения, включая:
- Операционную систему (даже с правами ядра)
- Гипервизоры (VMM) и виртуальные машины
- Системные администраторы с физическим доступом к машине
- Даже сам процессор Management Engine (ME)
Расширения: Intel SGX
- Энклавы (Enclaves)
- Это изолированные регионы памяти, защищённые аппаратно.
- Их содержимое (и код, и данные) автоматически шифруется контроллером памяти перед записью в RAM и расшифровывается при чтении обратно в процессор.
- Ключи шифрования генерируются аппаратно и уникальны для каждого процессора.
Расширения: Intel SGX
- Жизненный цикл энклава
- Создание (ECREATE): Приложение инициирует создание энклава в своей адресной памяти.
- Загрузка кода/данных (EADD): Критический код и данные загружаются в энклава. На этом этапе их целостность измеряется (хэшируется), создавая уникальный "отпечаток" (MRENCLAVE).
- Инициализация (EINIT): Энклава "запечатывается". После этого никакой код, даже с привилегиями ядра, не может изменить его содержимое. Любая попытка модификации приведёт к уничтожению энклава.
- Вызов (ECALL): Внешнее приложение может "войти" в энклава через специальные защищённые точки входа для выполнения кода внутри.
- Выход (OCALL): Код внутри энклава может выйти наружу (в небезопасное пространство) для вызова сервисов ОС (например, для работы с файлами или сетью), но делает это через строго определённые интерфейсы.
Расширения: Intel SGX
- Аттестация (Remote Attestation)
- Энклава генерирует криптографический отчёт, который включает её "отпечаток" (MRENCLAVE) и данные внутри.
- Этот отчёт подписывается аппаратным ключом, вшитым в процессор и известным только Intel.
- Удалённая сторона проверяет эту подпись через службу аттестации Intel.
- Если проверка проходит, сервер может быть уверен, что общается с доверенным кодом, и может передавать ему секретные данные (например, ключи шифрования, персональные данные).
- Энклава может "запечатать" свои данные перед выключением, зашифровав их ключом, привязанным либо к самому энклава, либо к процессору. Позже, при следующем запуске, тот же самый энклава (или другой, но с тем же идентификатором) может "распечатать" эти данные. Это позволяет сохранять состояние между сеансами работы.