Документация проектирования
Содержание
Проект архитектуры Проект интерфейса пользователя Основные структуры данных Проект подсистемПроект архитектуры
Детальное разбиение системы на подсистемы и модули, высокоуровневое описание взаимодействия подсистем и модулей:Программная система состоит из нескольких подсистем:
- Интерфейс;
- Поиск слова по точному совпадению;
- Поиск слова по параметрам;
- Поиск контекста слова;
- Внешняя база данных.
Структуру проекта и каждой подсистемы представим в виде следующей схеме:
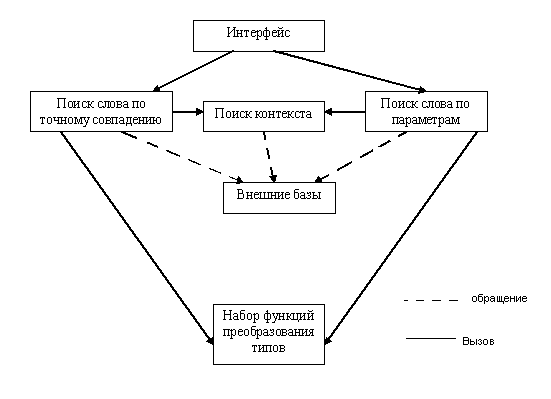 Описание взаимодействия между подсистемами и модулями:
Описание взаимодействия между подсистемами и модулями:
В начале пользователь в своём браузере набирает Web-адрес системы (http://smalt/karelia.ru/~orion/Smalt/Smalt.php3). Перед пользователем открывается подсистема «Интерфейс». В ней пользователь выбирает вариант поиска. По умолчанию выбран вариант поиска по точному совпадению. По желанию пользователь по специальной гиперссылке может перейти к варианту поиска по параметрам. В данной подсистеме имеется набор полей, необходимых для заполнения. После чего осуществляется переход к подсистемам поиска. Данная система также имеет средства помощи набора специальных символов и ссылки на информацию о данном проекте. В случае если выбран вариант поиска по точному совпадению происходит переход к системе поиска по точному совпадению. При этом данной подсистеме передаётся искомое слово. Подсистема поиска по точному совпадению преобразует искомое слово к виду, согласованному с видом слов, хранимых во внешней базе. Для этого она вызывает процедуру преобразования кодов букв искомого слова из десятеричного в шестнадцатеричное представление. После чего устанавливает соединение с базой данных, находящейся на сервере. Далее в подсистеме формируется запрос к базе данных. После чего запрос отправляется на сервер. После получения ответа подсистема расшифровывает результат. Если результатом явился пустой ответ, то выводится сообщение об отсутствии искомого слова. Если же результат запроса не пустой, то посредством встроенных процедур полученная информация преобразуется к виду, понятному пользователю. Для этого используются процедуры преобразования закодированных символов к кодировке UTF, а также преобразования последовательности цифр к информации вида: название признака – его значение. Информация по преобразованию типа содержится в модуле function.php, а информация, необходимая для расшифровки последовательности символов в базе GRMPAR.GDB. После расшифровки информации она предоставляется пользователю в виде текста на html странице. В случае выбора варианта поиска по параметрам происходит переход к подсистеме поиска слова по параметрам. При этом подсистеме передаётся уже сформированная строка запроса. Данная строка формируется динамически во время формирований значений параметров запроса при помощи языка сценариев JavaScript. Подсистема, получив строку запроса соединяется с внешней базой данных и отправляет запрос. После чего, обработав ответ сервера, система выдаёт либо сообщение об отсутствии искомой информации, либо предоставляет имеющуюся информацию, преобразовав её способом, описанным в подсистеме поиска по точному совпадению. После того, как подсистемы поиска слов отработали и информация представлена на обозрение пользователя, для каждого слова предоставляется возможность найти контекст, в котором содержится данное слово. Также предоставляется возможность вернуться в подсистему интерфейс. В случае выбора поиска контекста, происходит переход в подсистему поиска контекста слова. В данную подсистему передаётся вся информация, известная о данном слове. Подсистема формирует строку запроса к базе данных, содержащей тексты (В данной базе каждому слову из текста сопоставлен набор грамматических признаков). После получения ответа, результат расшифровывается. Если результатом явился пустой ответ, то выводится сообщение о сбое системы и просьба обратиться к администратору сервера. Стандартным результатом является набор цифр, характеризующий идентификационный номер текста, номер абзаца в тексте и номер предложения во внешней базе данных. Пользователю предоставляется предложение из текста и ссылка на текст целиком. В случае если число текстов, содержащих данное слово, превышает десять, то они выводятся в блоках по десять. На данном этапе планируется организовать простой поиск по базе данных. В случае, если реализация данных подсистем не натолкнётся на сложности, связанные с созданием и отладкой, то планируется разработка и реализация методов, позволяющих быстрее искать тексты (примером является создание хэш-таблиц, ознакомление с методами поиска, реализованными в системе Яndex, и др.). После предоставления информации, полученной при работе подсистемы предоставляется возможность перехода в подсистему интерфейс.
Проект интерфейса пользователя
Разрабатываемый Грамматический словарь Русского Языка XIX будет размещен в Интернете на сайте: http://smalt.karelia.ru/~orion
Главная страницаПерейдя по вышеуказанной ссылке, пользователь окажется на главной странице, с которой ему будут доступны все функции разрабатываемого словаря.
Главная страница состоит динамической и стационарной частей. На стационарной части страницы находится логотип проекта и главное меню. Динамическая часть регулярно обновляется, отображая реакцию программы на запросы и действия пользователя.
Динамическая часть главной страницы содержит краткое описание Грамматического словаря и небольшое руководство по его использованию.
Посредством главного меню пользователь в любой момент времени может вернуться на главную страницу («Главная»), обратиться к функциям поиска в словаре («Поиск»), посмотреть текущее содержимое словаря («Словарь») и информацию о его создателях («Авторы»), познакомиться с произведениями(«Произведения»).
Страница поиска
При переходе по ссылке «Поиск» пользователь оказывается на странице поиска.
Посредством функций, доступных на данной странице, пользователь может осуществить поиск хранящихся на сервере слов и связанных с ними текстов. Также поиск может осуществляться и по грамматическим признакам.
Пользователю требуется выбрать соответствующий тип поиска и нажать на кнопку «Выбрать».Если был выбран поиск по словам, то откроется страница поиска по словам, иначе - по грамматическим признакам.
Страница поиска по словам
Для ввода искомого слова на странице находится специальное поле. Также для удобства на странице представлены все буквы русского алфавита и три буквы древнерусского алфавита. При нажатии на любую из букв, выбранная буква вставляется в поле ввода.
Страница результатов поиска
После нажатия на кнопку найти осуществляется поиск и переход на страницу результатов поиска. Если искомое слово отсутствует на сервере, выводится сообщение: «Искомое слово в базе не найдено». В случае, если искомое слово найдено в БД, то оно выводится вместе со своими грамматическими признаками. Также пользователю предоставляется возможность посмотреть контекст, в котором найденное слово встречается с введенными грамматическими признаками. Для этого необходимо нажать на кнопку «Рассмотреть контексты». Страница поиска по грамматическим признака
Для поиска по грамматическим параметрам на странице представлены специальные поля выбора грамматических признаков: части речи, времени и рода.
Поиск будет осуществлен при нажатии на кнопку «Сохранить». При нажатии на эту кнопку будет выведен список слов, с соответствующими грамматическими признаками. При нажатии на конкретное слово, оно выводится вместе со своими грамматическими признаками. Также пользователю предоставляется возможность посмотреть контекст, в котором найденное слово встречается с введенными грамматическими признаками. Для этого необходимо нажать на кнопку «Рассмотреть контексты».
При нажатии на кнопку «Очистить», стирается содержимое полей ввода и грамматических признаков.
Страница словаря
Нажав на ссылку «Словарь», находящуюся в главном меню, пользователь переходит на страницу словаря. На данной странице отображается меню, состоящее из 29 букв русского алфавита. При нажатии на любую из букв, на данной странице отображается список слов, начинающихся на выбранную букву.
Страница результатов поиска
После нажатия на букву алфавита, с которой начинаются искомоеыет слова будет осуществляется поиск и переход на страницу результатов поиска. Если искомые слова отсутствует на сервере, выводится сообщение: «Слов, начинающихся с данной буквы нет». В случае, если искомые слова найдены в БД, то они выводится на страницу. При нажатии на конкретное слово, оно выводится вместе со своими грамматическими признаками. Также пользователю предоставляется возможность посмотреть контекст, в котором найденное слово встречается с введенными грамматическими признаками. Для этого необходимо нажать на кнопку «Рассмотреть контексты». Страница разработчиков
Для просмотра информации о создателях данного проекта, необходимо нажать на ссылку «Авторы» в главном меню. На странице авторов находится краткая информация о каждом из разработчиков. Призведения
Для того, чтобы познакомиться со списком произведений, имеющимися в БД, и с самими текстами, необходимо нажать на ссылку «Произведения» находящуюся в главном меню. На экран пользователя выведется список всех произведений. При нажатии на конкрентное название, откроется в отдельном окне текст произведения.
Основные структуры данных
Основной структурой данных, используемой нами, является БД Smalt. Структура БД, имеющейся у нас на данный момент, следующая:
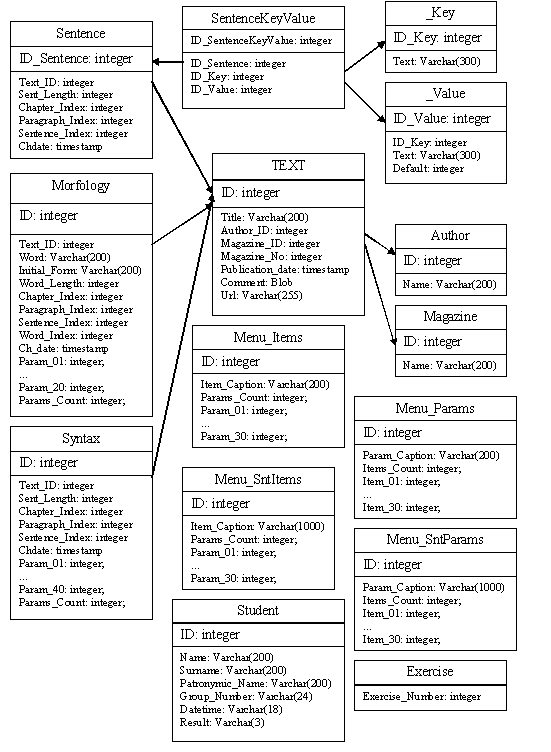
Таблица Text содержит информацию о текстах (автор, журнал, дата публикации). Содержит связи с таблицами Author, Magazine.
Таблица Morfology наиболее информативна для нас. Она содержит слова, коды их грамматических признаков и координаты в тексте.
Таблицы Menu_Items, Menu_Params содержат информацию о преобразовании кодов значений в сами значения. Связаны только на
программном уровне.
Таблицы Syntax, Menu_SNTItems, Menu_SNTParams аналогичны таблицам Morfology, Menu_Items, Menu_Params только для
синтаксических признаков. Для нас они не представляют никакого интереса.
Таблицы Sentence, SentenceKeyValue, Exercise, _key, _Value, Student также нам не нужны.
Отметим, что слова (поле Word в таблице Morfology) в этой БД хранятся в интерпретации XIX века (в Unicode-кодировке).
При программировании целесообразно использовать следующие структуры данных:
1) Запись для хранения координаты слова в тексте. Содержит № текста, № главы, № абзаца, № предложения и № слова.
В зависимости от стиля программирования, можно также применить 5-и мерный массив.
2) Структура Words вида:
W – строка, содержащая слово в кодировке Unicode
P[1..20] – целочисленный массив для хранения кодов грамматических параметров слова.
3) Структура Pars вида:
ParCount – целое число, содержащее число выбранных параметров
ParName[1..20] – массив строк, содержащий выбранные параметры
Items[1..20][0..20] – целочисленный массив для хранения кодов выбранных значений (1-ый индекс соответствует
параметру, элемент Items[i][0]содержит число выбранных значений для параметра i).
Проект подсистем
Подсистема «Интерфейс»: Данная подсистема выполняет роль основной подсистемы в нашем проекте, так как именно она будет являться проводником по нашей системе и осуществлять взаимодействие между пользователем и системой. Каждая её часть будет описана в отдельном модуле. Таким образом в состав данной подсистемы входит 5 модулей. Представим это графически:Условные обозначения: - М1 - модуль, представляющий данный проект - М2 - модуль, представляющий поиск - М3 - модуль, представляющий словарь - М4 - модуль, представляющий авторов и создателей данного проекта - М5 - модуль, содержащий подробное описание данного проекта Интерфейс с другими подсистемами: Данная подсистема взаимодействует с остальными подсистемами. В каждом отдельном случае, в зависимости от текущего работающего модуля система передаёт определённый набор информации. Она взаимодействует с остальными подсистемами, если текущими модулями являются М2 и М3. Если текущим модулем является М3, то подсистема передаёт в качестве параметра букву алфавита, с которой будут начинаться слова. По умолчанию это буква А. Если текущим модулем является М2, то подсистема передаёт искомое слово и/или грамматические признаки. Точнее строковую переменную, характеризующую искомое слово и набор переменных, характеризующий грамматические признаки. Поиск по точному совпадению: Данная подсистема состоит из одного модуля, содержащего набор функций. Часть функций вызываются из вспомогательного модуля functions.php. Интерфейс с другими подсистемами: Данная подсистема получает из подсистемы интерфейс строковую переменную, характеризующую искомое слово и при помощи внутренних функций, а также при помощи информации, получаемой из вспомогательного модуля GRMPAR.GDB при помощи sql-запросов, возвращает в подсистему интерфейс результат поиска. Т.е. слова и их характеристики. Поиск слова по параметрам: Данная подсистема состоит из одного модуля, содержащего набор функций. Часть функций вызываются из вспомогательного модуля functions.php. Интерфейс с другими подсистемами: Данная подсистема получает из подсистемы интерфейс набор строковых переменных, содержащий имена выбранных пользователем параметров. После чего запускается обработчик параметров, формирующий запросы к вспомогательному модулю GRMPAR.GDB и возвращающий результат в подсистему интерфейс. Т.е. слова и их характеристики.